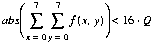
Performance Enhancement of H.263 Encoder Based On Zero Coefficient Prediction
The H.263 video codec is the ITU-recommended standard for very low bitrate video compression. Currently, H.263 encoding and decoding is the predominant technology used in videoconferencing across analog telephone lines, optimized at rates below 64 kbits/s. In fact, in February of 1996, after a call for new technology, tests performed by the MPEG-4 committee determined that H.263 outperformed all other algorithms that were optimized for very low bit rates.
Although a primary goal of the H.263 encoder is to represent information as compactly as possible without compromising video fidelity, it is also very important to reduce the computational requirements of the encoder. Reducing complexity allows the encoder to dedicate more resources to other functions, such as processing more video frames in a given time, or improving the quality of the audio representation.
In this paper, we propose a method that reduces the computational requirements of the encoder, while still upholding picture fidelity and remaining compatible with the H.263 bitstream standard. Our method is motivated by our observation that, often, a substantial number of inter-macroblocks in the encoder are reduced to all-zero values after quantization. We have developed a method of predicting when those macroblocks will quantize to zeros, which in turn allows us to eliminate the computation that would normally be required for those macroblocks. For our performance studies, we utilized the latest software version of H.263 written by Telenor (version 2.0), which is currently the most widely distributed public-domain software implementation of H.263. A brief introduction to the H.263 encoder is given in section 2.
In order to more accurately understand the impact of our algorithm on encoder performance, we began by optimizing the Telenor v2.0 software. This optimization, described in section 3, improved the encoder performance by four times its original speed. Also described in this section is a characterization of the encoder, before and after optimization. Next, in section 4, we describe our proposed algorithm for prediction of the all-zero macroblock condition and show how this observation can be used to improve performance in the motion estimator, discrete cosine transform (DCT), and quantizer. Finally, we present results in section 5, and we conclude in section 6. 2 H.263 Encoder Description
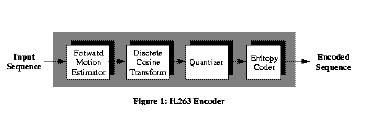
The general form of an H.263 encoder is shown in Figure 1 below. Its input is a video sequence, composed of a series of non-interlaced frames with luminance and two chrominance components associated with them. Because the human visual system is more sensitive to luminance information, the H.263 encoder expects the luminance information to be sampled at twice the rate of the chrominance information, in both horizontal and vertical dimensions. Therefore, each pixel in a frame has one luminance value associated with it, but it shares the chrominance information with three neighboring pixels.
In the baseline encoder, all frames in a video sequence are categorized as either I-frames or P-frames. I-frames, or intra-frames, are encoded without reference to any other frame in the sequence, in much the same manner that a still image would be encoded. In constrast, P-frames, or (predicted) inter-frames, depend on information from a previous frame for its encoding. Each frame in the sequence is further subdivided into "macroblocks," which consists of a 16x16 pixel luminance square, plus its corresponding two 8x8 chrominance squares. Macroblocks in an I-frame are intra-macroblocks, as they are all encoded independent of other macroblocks. In most cases, macroblocks in P-frames are inter-macroblocks, which depend on a previous macroblock for information. Under special cases, some macroblocks in P-frames can also be intra-macroblocks.
Inter-macroblocks experience an extra step of encoding that intra-macroblocks do not. This extra step is known as the motion estimator, and the goal is to predict the pixel values of the target macroblock from the values of a macroblock in a previous, reference, frame. Various search algorithms, such as an exhaustive search, can be used to determine which macroblock best predicts the target macroblock. This best-matching predictor is typically determined by calculating the sum of the absolute differences (SAD) between the two macroblocks' luminance values; The macroblock with the lowest SAD value is considered the best predictor.
When this best-prediction macroblock is found, its location is represented by a motion vector, which indicates the change from the target macroblock location to the prediction-macroblock location. Therefore, each inter-macroblock can be represented by two pieces of information: its motion vector, which indicates the location of the best-matching macroblock in the reference frame, and the prediction error, which is the difference between the prediction and the target macroblock pixel values.
The next step in the encoding process is that of the Discrete Cosine Transform (DCT). The DCT is a two-dimensional linear transformation that maps values in the spatial domain into the frequency domain. For inter-macroblocks, it is the prediction error that is transformed. For intra-macroblocks, the pixel values themselves are directly transformed. Instead of operating on an entire macroblock at one time, the DCT subdivides the macroblock into four 8x8 pixel squares, called "blocks", and operates on each block.
The DCT frequency-domain coefficients for each block are then sent through a quantizer, which maps the coefficient values into discrete values called reconstruction levels. In H.263, the step size, or distance between reconstruction levels, is constant, defined by 2Q, where the variable Q is called the Q-factor. Q can range from 1 to 31. All coefficients within an inter-macroblock are quantized using the same Q value, regardless of position in the block, but the Q value can change between macroblocks. Because quantization introduces loss, and higher Q values introduce more loss than lower Q values, varying the Q value is a method used for rate control, i.e., to control the flow of information encoded in the final bitstream. Finally, the quantized coefficients are entropy coded and sent to the decoder, along with the motion vectors and other relevant formatting information. 3 Encoder Optimization and Characterization
In order to more acccurately measure our encoder performance, we first optimized the Telenor software encoder. To do this, we profiled the baseline encoder to determine which parts of the code consumed the greatest amount of computational resources. The profiling information was obtained using the DPAT (Distributed Performance Analysis Tool) utility. DPAT gathers data on a program by suspending the process periodically and taking samples of the program, using a user-specified sampling interval of 10 milliseconds. We collected the data for the profiler, as we did for all future results presented in this paper, using an HP 9000/712 workstation with an 80 MHz processor clock and 32 Mbytes of RAM.
Using the profiling information we obtained, we then tried to increase the efficiency of computationally-intensive areas using techniques such as loop unrolling and algorithm substitution. We found that the two most effective changes occurred in the motion estimator and inverse DCT. For the motion estimator, this was accomplished by replacing absolute value function calls with if-then macros within the block matching routines. We replaced the IDCT algorithm with a fast IDCT algorithm -- also supplied by Telenor -- and added clipping in the fast IDCT algorithm to conform to the H.263 standard. The two changes we mentioned reduced the computation time of the motion estimator and inverse DCT by 4-5 times their original value.
Figure 2 shows the results of optimizing the Telenor v2.0 software encoder. The chart identifies functional parts of the encoder and the amount of time that each part demands. The entire bar length represents the total encoder execution time, which is also subdivided proportional to the execution time of the individual parts. We collected this data from the baseline encoder, which used no rate control (i.e., Q is held constant for all macroblocks). The motion search provided by the encoder for the motion estimation is an exhaustive search. We chose a Q value of 14 for our profiling data.
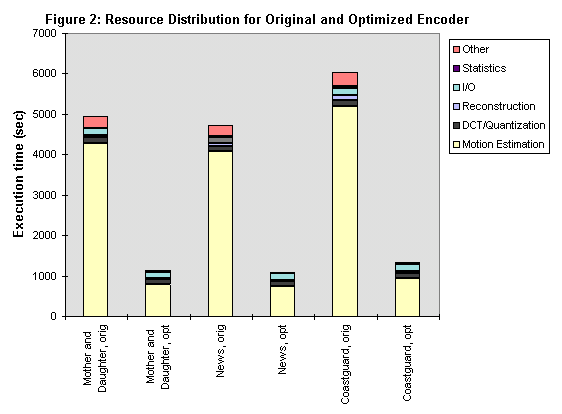
Much of the functional parts in Figure 2 are self-explanatory. "Reconstruction" includes the inverse quantization and inverse DCT, as well as reconstruction of the frame. These steps simulate the actions of the decoder, so that the reconstructed frames can be used as reference frames in the motion estimator for future frame encoding. "I/O" primarily involves writing and reading images to and from disk. "Statistics" refers to statistics-gathering capabilities in the encoder, which track information such as bit rate and video fidelity. "Other" includes functions such as pixel interpolation, memory allocation and management, and the computation of bit stream syntax needed for the decoder.
The sequences that we used for profiling are the same sequences which are used for all of our studies. To best characterize algorithm performance, we chose sequences with extremely varying content. All of them are standard test sequences provided by the LBC committee, which developed H.263, and each consist of 300 CIF-sized frames. (CIF is defined as 352x288 pixels in dimension.) Mother and Daughter is a typical head-and-neck sequence with very little movement. Coastguard is a fast-moving panning sequence. News has a combination of fast and slow motion, which includes rotational movement and scene changes. An input sequence such as Coastguard is not typical of the type of sequence that H.263 is best suited for, but we include it in our study for completeness. Because each test sequence consists of 300 frames, the average number of frames encoded per second can be derived from Figure 2 by dividing the total execution time into 300.
Figure 2 shows that, for both the original and optimized encoder, total execution time does vary with the input sequence. This is primarily due to the changing complexity of the motion estimator, because the other functional parts have relatively constant execution time. The only exception is the reconstruction time for Coastguard, which is larger than for the other sequences; this is because Coastguard generates significantly more error coefficients than its counterparts, which in turn require greater computation for reconstruction. Overall, optimization of the encoder reduced its computation time by four times its original value.
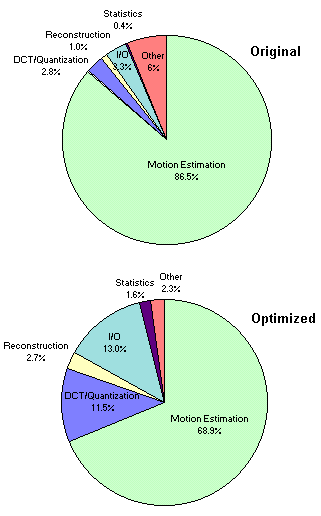
Figure 3 presents a breakdown of the execution time for the original and optimized encoder. The percentage distribution was very similar for all three test sequences, so only the results for the Mother and Daughter sequence are shown here. In both the original and optimized code, the motion estimation computation dominates, consisting of 69% and 87%, respectively, of the total encoding time. After optimization, however, the DCT/Quantization and I/O functions become significant, although still small, portions of the encoder.
In addition to the exhaustive motion search provided in the Telenor code, we also implemented two other well-known search algorithms for our experiments. The first is Jain and Jain's 2-d logarithmic search [1]; the second is the three-step hierarchical search, as defined by the MPEG committee [2] (which they call the logarithmic search also). Both algorithms are popular fast motion-search algorithms, which compromise video fidelity and bitrate slightly for approximately a 200% speedup. The distribution of computation time for the exhaustive, 2-d logarithmic, and three-step hierachical searches are shown in Table 1, which are all based on the optimized encoder.
 Table 1: Execution time in seconds (and percentage of total) for optimized
encoder
Table 1: Execution time in seconds (and percentage of total) for optimized
encoder
------------------------------------------------------------------------------------------------------
Sequence Search Motion DCT/ Recon I/O Statistics Other
Name Algorithm Estimator Quantizer
While the encoding times vary, the percentage distribution of execution time between sequences is fairly consistent for a given search algorithm. Using an exhaustive search, the motion estimation computation dominates at 67%-69% of the total encoding time, in spite of the optimization. However, using the 2-d logarithmic and three-step hierarchical searches, the motion estimation computation drops to about 25%-27% of the total encoding time. In the latter case, the computation associated with the DCT/Quantizer (24%-27%) and the I/O (29%-33%) become significant. Therefore, the three components which utilize the largest amount of computational resources are the motion estimator, the DCT/Quantizer, and the I/O. Since the speed of the I/O is beyond the control of the software, improving the performance in the former two areas could prove to be advantageous. Our efforts for the remainder of the paper concentrate on this goal. The next section begins by introducing our proposed algorithm and then describes how it can improve the encoder performance even further by reducing computation in the motion estimator and DCT/Quantizer. 4 Prediction of All-Zero Quantized Coefficients
The motivation for our proposed algorithm comes from the observation that, for most sequences at very low bit rates, a significant portion of all macroblocks -- typically 30% to 65% -- have DCT coefficients that are all reduced to zero after quantization. Table 2 illustrates this observation for our three test sequences. The proportion of all-zero quantized (AZQ) macroblocks is somewhat sequence-dependent, but, for bitrates that H.263 operates around, it is not unreasonable to expect that more than 50% of all inter-macroblocks will reduce to zero after quantization. In fact, for our sequences, at average bitrates around 64 kbits/sec, the number of AZQ macroblocks increases to 87% or more. If it were possible to predict when this happens, it would be possible to eliminate a portion of the computation associated with those macroblocks. A substantial savings can be achieved in this way.
Table 2: Fraction of inter-macroblocks which quantize to all zeros,
unmodified encoder
--------------------------------------------------------------------------------
Q Mother and Daughter News Coastguard
Bitrate % all-zero Bitrate % all-zero Bitrate % all-zero
(kbits/sec) mblocks (kbits/sec) mblocks (kbits/sec) mblocks
We propose that successful prediction of AZQ macroblocks can be performed by using the dc coefficient of the DCT as an indicator. We have observed that, in the majority of cases, the dc coefficient has a larger magnitude than all other coefficients in a transformed block. Since the coefficients in a block will quantize to zeros only if their magnitudes are less than 2Q, it follows that, when our observation holds true, a block will quantize to zeros when the dc coefficient has a magnitude less than 2Q.
Let f(x,y) represent the prediction error in an 8x8 block. Then the two-dimensional forward DCT transform used by each 8x8 block is given by
(1) 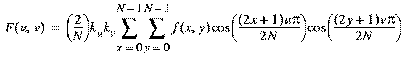
for u,v=0,1,...,N-1, where
(2) 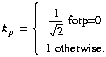
The dc term of the DCT corresponds to the point at u=v=0, which simplifies to
(3) 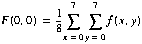
when N=8.
Therefore, the coefficients in the 8x8 block will quantize to zeros whenever the magnitude of F(0,0) is less than the quantization step size, i.e.,
holds true. This condition is fairly inexpensive to compute. Also, the criterion is advantageous in that it is independent of input sequence characteristics and adapts with quantization step size (2Q).
The algorithm we propose to detect AZQ macroblocks is therefore given as follows: Calculate the dc value for each 8x8 luminance block in the macroblock. If the dc value for a block has a magnitude less than 2Q, then assume that the block will quantize to zero. If all four blocks meet this criterion, then the macroblock is an AZQ macroblock.
In practice, we have found that this algorithm can perform better when we tighten our condition slightly to
(5) 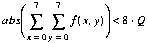 .
.
Although this more stringent criterion will overlook some macroblocks that should be identified as AZQ macroblocks, it also reduces the number of incorrectly selected macroblocks, which can degrade the final picture fidelity.
Our proposed algorithm is one of several variations for identifying AZQ macroblocks using our dc prediction scheme. More information on this, in which accuracy can be traded for performance, can be found in [3]
We suggest two methods by which our algorithm can improve H.263 encoder performance. The first is to use the prediction to save computation in the DCT and Quantizer. This is shown in Figure 4.
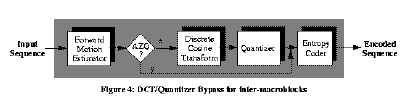
After the motion estimator has finished and the inter-macroblock error is known, we use our prediction method to determine which inter-macroblock errors should be sent to the DCT. If indeed a macroblock's coefficients will quantize to zero, there is no need to calculate the DCT coefficients, nor is there need to quantize them. Therefore, those macroblocks whose errors pass the AZQ test skip the DCT and quantization operations and go directly to the entropy coder. The coefficients for these macroblocks are set to zero. We only perform this test on inter-macroblocks, because intra-macroblocks are less likely to satisfy our assumption that the dc DCT coefficient has the largest magnitude.
A second method to improve encoder performance is to modify the motion estimation search algorithm using our prediction method. Normally, to determine a best match against a target macroblock, the target macroblock is compared against every macroblock in the search region, as dictated by the search method. The encoder tracks the best-performing macroblock at every point during the search, updating this information whenever a better match is found. Only after all macroblocks have been considered is the best match known.
By combining the motion search with our prediction method, how ever, there is now an option to terminate the motion search early, before all macroblocks in the search have been considered. Should a best-matching macroblock's error generate all zeros after quantization, the search may be discontinued, since future macroblocks that match well with the target macroblock will most likely be AZQ as well. Therefore, we modify the traditional motion search to include an AZQ test whenever a macroblock in the search is determined to be the best-so-far. If the macroblock passes the test, then the motion search terminates. 5 Results
As mentioned earlier, all results presented in this paper were obtained by running the optimized Telenor v2.0 H.263 encoder on an HP 9000/712 workstation, which has a 80 MHz PA-RISC 1.1 processor and 32 Mbytes of RAM. The test sequences consist of three progressive, 300-frame CIF sequences, with each frame represented in YUV format, and chrominance values subsampled 2:1 in both directions. The three test sequences -- Mother and Daughter, Coastguard, and News -- have varying amounts of motion, textures, and camera effects. To avoid introducing any biasing factors, the encoder does not utilize any rate control mechanism; rather, it fixes the quantization step size (2Q), which results in variable bit rates per frame during encoding.
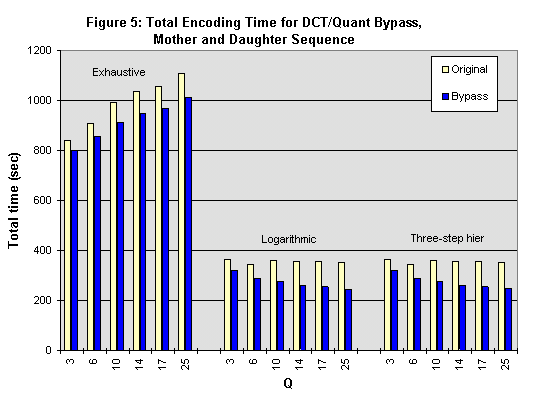
Results using the DCT/Quantizer bypass are given in Figures 5 through 7 for the Mother and Daughter sequence, using the algorithm described in Section 4.2, and using equation (5) as the criterion. We present only the data for Mother and Daughter because the data for the other two sequence have similar characteristics. For all three sequences, not only is the total encoding time reduced, but there is also a savings in bitrate, with virtually no visible loss in video fidelity.
Based on Figure 5, the relative improvement of the DCT/Quantizer bypass algorithm is better with the fast search algorithms than with the exhaustive search, incorporated. An encoder using either the logarithmic or three-step hierarchical search has speed-ups that are several times larger than one using an exhaustive search. For example, in Mother and Daughter, the reduction in total encoding time for the fast search algorithms is as high as 30%, but the reduction in time for the exhaustive search is at most 9%. This is because the motion estimation consumes a much larger portion of the total encoder resources when an exhaustive search is used. The speedup in the DCT/Quantizer (140% to 350%, depending on Q) is fairly constant, regardless of the search algorithm, but this savings will have relatively less impact when the DCT/Quantizer is a smaller proportion of the total encoding time.
Another characteristic that differentiates the encoder using the exhaustive search from the other two search algorithms is the change in execution time with increasing Q value. For the fast motion searches which incorporate the DCT/Quantizer bypass, as Q increases, the total execution time decreases. However, for the exhaustive case, total execution time increases with increasing Q value. This characteristic is another consequence of the dominating motion estimator associated with the exhaustive search. In general, as Q values increase, our zero-prediction becomes more effective, since there are more existing AZQ macroblocks. However, as Q values increase, more inaccuracies are introduced into the reconstructed frames, which in turn lengthens the block matching time in the motion search. The block matching time increases because of an early cutoff mechanism in the SAD calculation for each macroblock, which becomes more ineffective as more inaccuracies arise. For the fast search algorithms, the DCT/Quantizer is a significant enough portion of the encoder that the effects of the DCT/Quantizer bypass dominate, and the entire encoding time decreases with increasing Q. However, in the exhaustive case, the motion estimation overshadows improvements in other parts of the encoder, and therefore the execution time still increases with increasing Q.
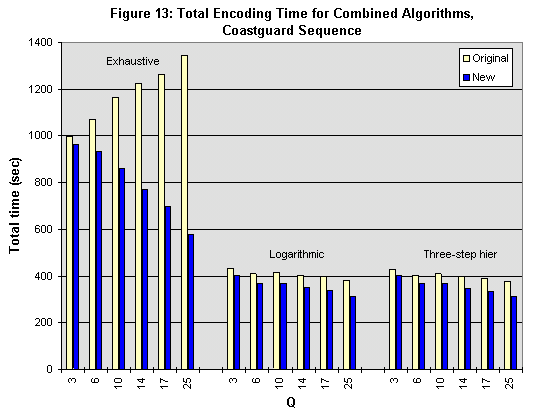
Although not shown here, the percentage of relative improvements in encoder performance is most pronounced in the Mother and Daughter and News sequences, but less dramatic for Coastguard. This will be true for all our results. For example, the DCT/Quantizer bypass improves the execution time of the Mother and Daughter and News sequences by 5%-30%. For the Coastguard sequence, the execution times are reduced by 1%-22%. Such a trend is consistent with the data in Table 2, which indicates that the original fraction of AZQ macroblocks for Coastguard is smaller; therefore, there are fewer opportunities for our algorithms to save computation.
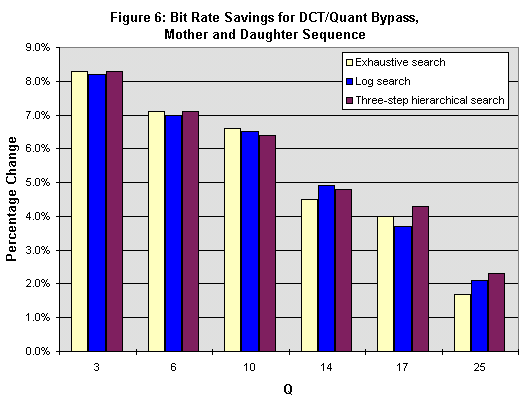
In addition to the speedup, the DCT/Quantizer bypass also reduces the total bit rate, as shown in Figure 6 for Mother and Daughter. The reduction in bit rate is primarily caused by false positive predictions by our algorithm, i.e., incorrect predictions that a macroblock is AZQ when in fact it is not. When a false positive prediction occurs, no information is sent representing that macroblock, whereas, in the original case, some nonzero coefficients were transmitted. Because the bit rate savings is caused by incorrect predictions, the savings will decrease with increasing Q values; at higher Q values, more macroblocks become AZQ, thus reducing the chance of an incorrect prediction. Bit rate savings range from 2% to 8% for Mother and Daughter, 5%-7% for News, and 4%-10% for Coastguard. The savings in bit rate is very consistent across the different motion search algorithms.
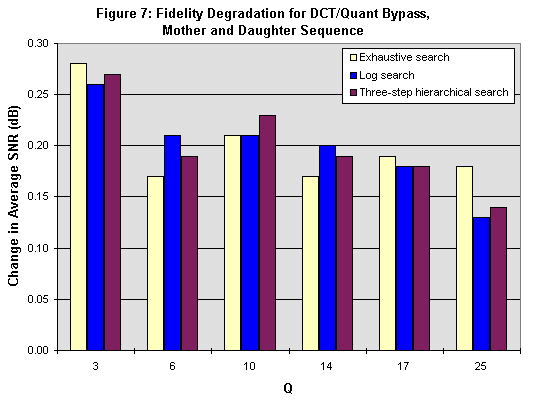
The degradation in fidelity due to the DCT/Quantizer bypass is small, as shown in Figure 7. In terms of SNR, the change in fidelity for Mother and Daughter resulted in no more than a .28 dB drop. Maximum fidelity degradations for News and Coastguard were .55 dB and .92 dB, respectively. Fidelity degradation is also caused by the false positive predictions of our algorithm, which bypass the DCT and quantizer for macroblocks that are not truly AZQ. Visually, the new sequences look no different than the original sequences, except in one case. In News, at high Q values, scene changes create a momentary change in chrominance for a handful of background macroblocks. Since Mother and Daughter and Coastguard do not contain scene changes, this effect was not noticed in the other sequences.
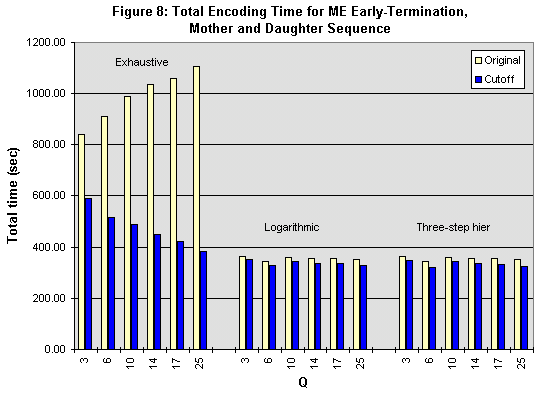
Figures 8 through 10 show the results of the early-termination algorithm for the Mother and Daughter sequence, as described in Section 4.3, using equation (4). The characteristics of the data is quite different from the characteristics resulting from the DCT/Quantizer bypass. For example, in Figure 8, the speedup is most pronounced now when the encoder uses the exhaustive motion search, which yields a 30% to 65% decrease in encoding time for Mother and Daughter. In contrast, the savings in execution time for the fast search algorithms range from 4% to 7% for Mother and Daughter. Early termination in the exhaustive search is more effective because a good match is typically found very early in the search; combined with AZQ prediction, many future macroblock comparisons are eliminated. With the fast search algorithms, however, the original number of macroblock comparisons is small, and therefore there is much less savings to gain. In addition, since the exhaustive search causes the motion estimator to dominate the encoding time, improvements in the motion estimator will be more noticeable using an exhaustive search. Note that with early termination, the execution time for all motion searches decrease with increasing Q values. This means that the computational savings caused by the early termination algorithm, which becomes greater at higher Q values, more than compensates for the increased computation required by the motion search at highter Q values. Characteristics are similar for the other two sequences, which is why their data is not displayed here. The speedups for News and Coastguard using the exhaustive search are 33%-62% and 4%-57%, respectively. For the fast motion searches, the speedups for News and Coastguard range between 1% and 7%.
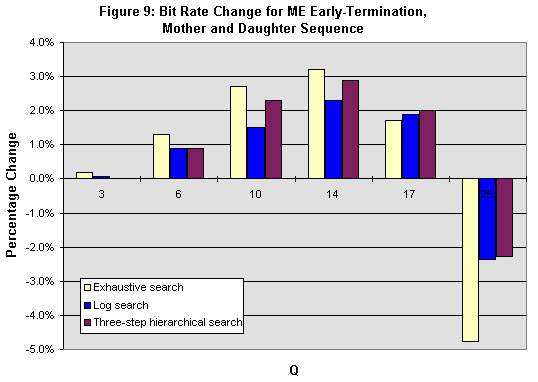
Figure 9 shows that the bitrate increases in most cases when using early-termination. The increases in bitrate are modest in Mother and Daughter and News -- between .3% and 5.7% for the former, and between .1% and .8% for the latter. Coastguard has larger rate increases, ranging from .3% to 13.7%. Recall that in the DCT/Quantizer Bypass, if a macroblock is incorrectly diagnosed as an AZQ macroblock, the macroblock's coefficients are effectively changed to zeros. This causes the bit rate to decrease, typically. In contrast, in the early-termination case, an AZQ prediction in the motion estimator does not guarantee that the macroblock's coefficients will ultimately be zero; the macroblock's coefficients will be zero only if the prediction is correct. If an incorrect (false positive) prediction occurs, it may increase the number of coefficients that need to be transmitted. Therefore, the final bit rate may increase.
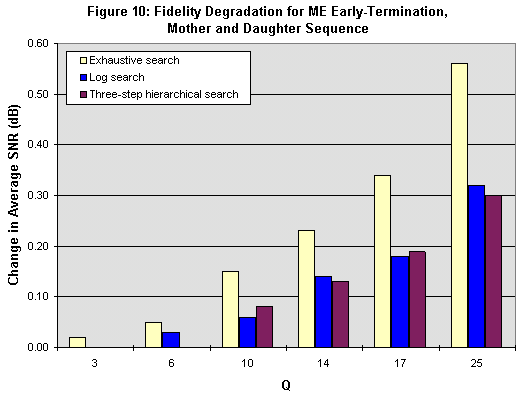
Again, the fidelity degradation is small. The change in SNR is below .5 dB for all the sequences except in one case. Visually, the sequences are indistinguishable from the original sequences except for Mother and Daughter at high Q values (Q>10). In Mother and Daughter, color smearing, which appears even in the original sequences, becomes more noticeable with early-termination incorporated.
AZQ prediction in the motion estimator is generally much more sensitive to predictor accuracy than AZQ prediction in the DCT/Quantizer. Prediction errors in the DCT/Quantizer are less noticeable because some of the error can be compensated by the motion estimator in the next encoded frame in terms of the motion vector, which has a small effect on the final bit rate. However, errors accumulated in the motion estimator immediately impact bit rate, because the error compensation will occur in the DCT/Quantizer, which would transmit more nonzero coefficients. AZQ prediction in the motion estimator is also more sensitive to the computational cost of the predictor. This is because, per macroblock, more AZQ tests are performed when doing early-termination than when doing the DCT/Quantizer bypass.
Our earlier data indicates that the DCT/Quantization bypass works best for the encoder when fast motion searches are employed, since the complexity of the DCT and Quantizer is a significant part of the total resources in those cases. Conversely, the early-termination technique in the motion estimator is most effective when the encoder employs an exhaustive search. Based on these results, we propose a hybrid algorithm, in which both techniques are used, depending on the type of motion search. If a fast motion search is implemented, then our algorithm will use a DCT/Quantization bypass. If an exhaustive, or otherwise motion-estimation-intensive, search is used, then our algorithm utilizes the early-termination technique in the motion estimator.
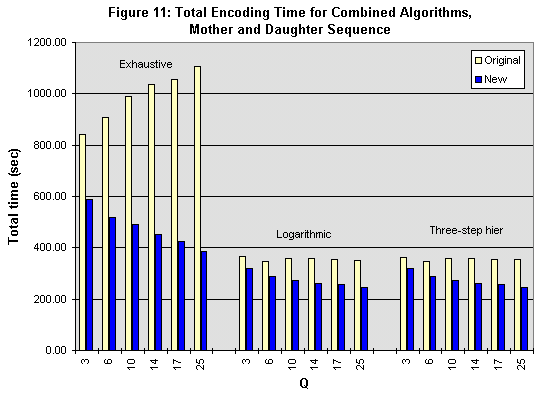
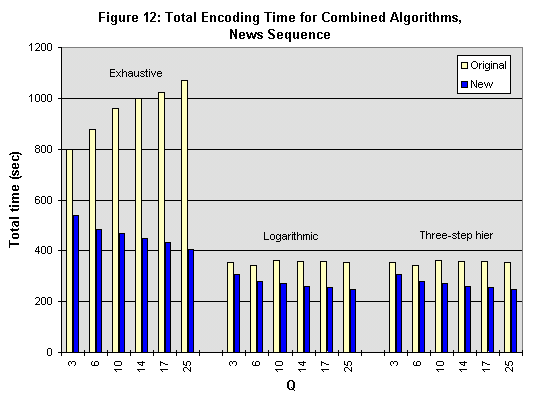
Figures 11 through 15 show the results of our combined algorithm. In terms of execution time, fairly significant gains are achieved with all three motion searches, from 3.5% to 65%, depending on the search and sequence type. Most of the lower gains are associated with Coastguard, whose bit rate is much higher than what is typically used for H.263 encoding.
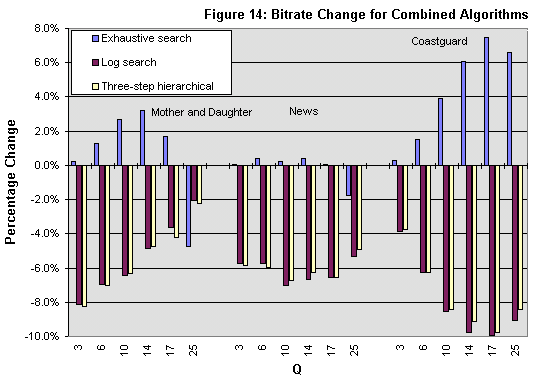
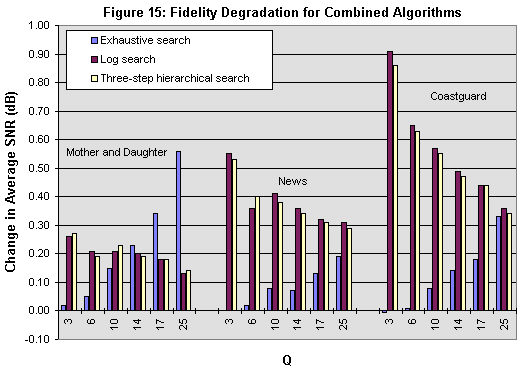
Because of the varying characteristics of the DCT/Quantizer bypass and early-termination algorithms, our combined algorithm yields a decrease in bit rate in some cases and an increase in others. The change in bit rate is no worse than an 8% increase and no better than a 10% decrease. In most cases, the fidelity degradation does not exceed .5 dB; in no case does the change in SNR exceed 1 dB.
In summary, our algorithm, which predicts all-zero quantized (AZQ) macroblocks in the H.263 encoder, provides several methods to save computation in the motion estimator, DCT, and quantizer. In general, the proposed DCT/Quantizer bypass algorithm is an attractive algorithm for systems which need to reduce computation time; for the fast motion search algorithms, which would be the natural choice under these conditions, execution time can be reduced by as much as 30%, with an additional savings in bitrate, and virtually no change in fidelity.
For the exhaustive search, the early-termination algorithm in the motion estimator can offer substantial savings -- up to 65% savings in time -- with very little sacrifice in bitrate and fidelity. We proposed a hybrid algorithm which utilizes both the DCT/Quantizer bypass and the early-termination in the motion estimator to optimize performance. Compared to the original (unoptimized) encoder, the final effect of all our improvements is to reduce computation in the encoder by four to nine times its original value. An initial 4x reduction is due to the optimization of the encoder. The additional improvement is due to our AZQ prediction technique, whose exact effects vary with the motion search type, input sequence type, and quantization step size.
We fully expect that the encoder performance can be improved even further using other techniques, such as employing subword parallelism [4]. Combined with today's faster workstations, it is not unreasonable to expect at least another order of magnitude decrease in total execution time, relative to our current results.
Under a few conditions, the fidelity degradation is visible and manifests itself as chrominance changes; no distortion appears in the luminance. This is because our algorithm predicts AZQ blocks solely on luminance values, which may be an inaccurate indicator for chrominance blocks. We are currently investigating more accurate prediction algorithms which take chrominance into consideration. 7 Bibliography
[4] R. Lee, "Subword Parallelism with MAX-2," IEEE Micro, vol. 16, no. 4, pp. 51-59, August 1996.