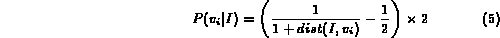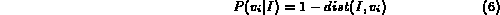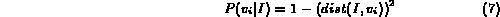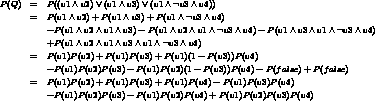97]
and commercial systems[F
97]
and commercial systems[F 95,BFG
95,BFG ] that have been built
recently.
Such an approach can be summarized as follows:
] that have been built
recently.
Such an approach can be summarized as follows:
MARS, Content based retrieval, Image database
While advances in technology allow us to generate, transmit, and
store large amounts of digital images, and video, research
in content based retrieval over multimedia databases is still at its infancy.
Due to the difficulty in capturing the content of multimedia objects
using textual annotations and the non-scalability of
the approach to large data sets (due to a high degree of manual effort
required in defining the annotations),
the approach based on supporting content-based retrieval over visual
features
has become a promising research direction. This is evidenced by
several prototypes[SC94,PPS94,MM95,MCO97]
and commercial systems[F95,BFG] that have been built
recently.
Such an approach can be summarized as follows:
Since automatically extracted visual features (e.g., color, texture etc.) are too low level to be useful to the users in specifying their information needs directly, content-based retrieval using visual features requires development of effective techniques to map higher-level user queries (e.g., retrieve images containing field of yellow flowers) to visual features. Mapping a user's information need to a set of features extracted from textual documents have been extensively studied in the information retrieval literature [SM83]. This paper describes how we have generalized these approaches for content-based retrieval over image features in the Multimedia Analysis and Retrieval System (MARS) being developed in our group at the University of Illinois.
Before we describe the retrieval approach used in MARS, we briefly review the retrieval process in modern information retrieval (IR) systems [SM83]. In an IR system, a document is represented as a collection of features (also referred to as terms). Examples of features include words in a document, citations, bibliographic references, etc. A user specifies his information needs to the system in the form of a query. Given a representation of the user's information need and a document collection, the IR system estimates the likelihood that a given document matches the users information needs. The representation of documents and queries, and the mechanism used to compare their similarity forms the retrieval model of the system. Existing retrieval models can be broadly classified into the following categories:
 be the set of
terms in a collection.
Each document is represented as a binary-valued
vector of length k where the
be the set of
terms in a collection.
Each document is represented as a binary-valued
vector of length k where the  element of the vector is assigned
true if
element of the vector is assigned
true if  is assigned to the document.
All elements corresponding
to features/terms not assigned to a document are set to false.
A query is a Boolean expression in which operands are terms. A document
whose set of terms satisfies the Boolean expression is deemed to be relevant
to the user and all other documents are considered not relevant.
is assigned to the document.
All elements corresponding
to features/terms not assigned to a document are set to false.
A query is a Boolean expression in which operands are terms. A document
whose set of terms satisfies the Boolean expression is deemed to be relevant
to the user and all other documents are considered not relevant.
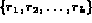 be the set of
terms in a collection. Both documents and queries are represented
as a vector of k dimensions where each element in the vector
corresponds to a real-valued weight assigned to a term.
Several techniques have been proposed to compute these weights,
the most common being tf.idf weights [SM83],
where tf refers to the term frequency in the document,
and idf is a measure proportional
to the inverse of its frequency in the collection.
Similarly, many similarity measures have been proposed between
the document and the query [SM83] the most common being
the cosine of the angle between the document and the query vectors.
be the set of
terms in a collection. Both documents and queries are represented
as a vector of k dimensions where each element in the vector
corresponds to a real-valued weight assigned to a term.
Several techniques have been proposed to compute these weights,
the most common being tf.idf weights [SM83],
where tf refers to the term frequency in the document,
and idf is a measure proportional
to the inverse of its frequency in the collection.
Similarly, many similarity measures have been proposed between
the document and the query [SM83] the most common being
the cosine of the angle between the document and the query vectors.
Given a document and a query, the system computes
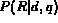 which represents the probability that the
document d will be deemed relevant to query q.
Using Bayes' theorem and a set of independence assumptions
about the distribution of terms in documents these probabilities
are computed and the documents are ranked based on these probabilities.
which represents the probability that the
document d will be deemed relevant to query q.
Using Bayes' theorem and a set of independence assumptions
about the distribution of terms in documents these probabilities
are computed and the documents are ranked based on these probabilities.
Traditionally, commercial IR systems have used the Boolean model. Systems based on Boolean retrieval partition the set of documents into either being relevant or not relevant and do not provide any
estimate as to the relevance of any document in a partition to the users information need. To overcome this problem, many variations of the term-weighting models and probabilistic retrieval models that provide ranked retrieval have been developed. The boolean model has also been extended to allow for ranking in the text domain ( p-norm model [SFV83]). Vector-based models and probabilistic retrieval models are in a sense related and provide similar performance. The primary difference being that while the vector models are ad hoc and based on intuitive reasoning, probability based models have a more rigorous theoretical base.
With a large number of retrieval models in the information retrieval literature, MARS attempts to exploit this research for content-based retrieval over images. In MARS, an image is represented as a collection of low-level image features (e.g., color features, texture features, shape and layout features extracted automatically) as well as a manual text description of the image. A user graphically constructs a query by selecting certain images from the collection. A user may choose specific features from the selected images. For example, using a point-and-click interface a user can specify a query to retrieve images similar to an image A in color and similar to an image B in texture. A user's query is interpreted as a Boolean expression over image features and a Boolean retrieval model (adapted for retrieval over images) is used to retrieve a set of images ranked based on the degree of match. Boolean queries provide a natural interface for the user to formulate and refine conceptual queries to the system using lower-level image features. For example, high level concepts like fields of yellow flowers or a sunset by a lake can be expressed as a boolean combination of lower level features. Such a mapping of high to low level concepts can be provided explicitly by the user or alternatively learned via user interaction by a relevance feedback mechanism.
Being able to support such conceptual queries is critical for the versatility of large image databases.
To see how MARS adapts the Boolean model for image retrieval,
consider first a query Q over a single feature 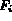 (say color represented
as a color histogram). Let
(say color represented
as a color histogram). Let 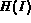 be the color histogram of image
I and
be the color histogram of image
I and 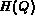 be the color histogram specified in the
query and
be the color histogram specified in the
query and 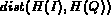 be the distance between the two histograms.
The simplest way
to adapt the Boolean model for image retrieval is to associate
a degree of tolerance
be the distance between the two histograms.
The simplest way
to adapt the Boolean model for image retrieval is to associate
a degree of tolerance
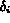 with each feature
with each feature 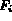 such that:
such that:
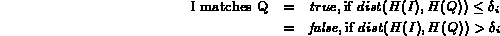
Given the above interpretation of a match
based on a single feature 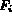 ,
an image I matches a given query Q if it satisfies the Boolean
expression associated with Q. For example, let
,
an image I matches a given query Q if it satisfies the Boolean
expression associated with Q. For example, let 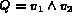 , where
, where
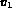 is some color histogram, and
is some color histogram, and 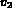 is a texture representation.
Image I matches Q if its color and texture representations are within
the specified tolerances of
is a texture representation.
Image I matches Q if its color and texture representations are within
the specified tolerances of 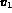 and
and 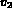 .
.
While the above straightforward adaptation of Boolean retrieval
can be used, it suffers from many potential problems.
First, it is not clear how the degree of tolerance 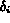 , for
a given feature
, for
a given feature 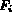 ,
should be determined.
If an a priori value is set for
,
should be determined.
If an a priori value is set for 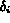 , it may result in poor
performance -- two images
, it may result in poor
performance -- two images 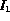 and
and 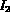 at the distance of
at the distance of
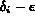 and
and
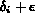 from a query q,
where
from a query q,
where 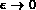 , are essentially very
similar will be considered as very different by
the system. While
, are essentially very
similar will be considered as very different by
the system. While 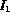 will be considered relevant to the query,
will be considered relevant to the query, 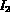 will
be considered as not relevant.
This problem may be alleviated if instead of fixed a priori
values for tolerance for a given feature,
will
be considered as not relevant.
This problem may be alleviated if instead of fixed a priori
values for tolerance for a given feature,
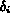 was computed dynamically for each
query based on the image collection. However, the approach
would still suffer from the fundamental restriction
of the basic Boolean retrieval in that it produces a unranked set of answers.
was computed dynamically for each
query based on the image collection. However, the approach
would still suffer from the fundamental restriction
of the basic Boolean retrieval in that it produces a unranked set of answers.
To overcome the above discussed problems, in developing MARS, we have adopted the following two extensions to the basic Boolean model that produce ranked list of answers.
Unlike the basic Boolean model, both the fuzzy and probabilistic Boolean models provide a ranked retrieval over the image sets. Furthermore, as one expects from Boolean models, both the fuzzy and the probabilistic Boolean models rank images based on queries corresponding to semantically equivalent Boolean expressions in the same order.
The rest of the paper is developed as follows. In Section 2, we describe the set of basic image features used in MARS including technique used to measure similarity between images based on a single feature. Section 3 is devoted to defining the Boolean retrieval models used in MARS and discussing the issues related to their efficient implementation. Section 4 discusses normalization of the low level features necessary to combine with each other. Experimental results that show the retrieval effectiveness of the developed models are discussed in Section 5 and finally Section 6 offers concluding remarks including a discussion of the work we are pursuing in the future.
The retrieval performance of an image database is inherently limited
by the nature and the
quality of the features used to represent the image content.
In this section, we briefly
describe the image features used in MARS and the corresponding distance
functions used for comparing
similarity of images based on the features. The discussion is
kept short since the purpose of
this section is only to provide
a background for discussing issues related to normalization
and ranked retrieval based on Boolean queries.
Detailed discussion on the rationale and the quality of the chosen features
can be found in references
[FFN 93,T
93,T 78,MCO97,M
78,MCO97,M 88,RSH96].
88,RSH96].
Color Features:
To represent color, we choose the
HSV space due to its de-correlated and uniform coordinates.
The color feature is represented using a color histogram.
Since V coordinate is easily affected by the lighting condition, we use only
HS coordinates to form an 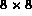 two-dimensional histogram.
To measure distance between two color histograms,
we compute the amount of non-overlap
between the two histograms which is defined as follows:
two-dimensional histogram.
To measure distance between two color histograms,
we compute the amount of non-overlap
between the two histograms which is defined as follows:
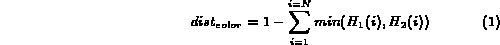
where 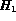 and
and 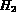 are the two histograms and N is the number of bins
used in the histogram. The above intersection based measure of distance
provides an accurate and efficient measure of (dis)similarity between
two images based on their color [SC94].
are the two histograms and N is the number of bins
used in the histogram. The above intersection based measure of distance
provides an accurate and efficient measure of (dis)similarity between
two images based on their color [SC94].
Texture Features:
To represent texture of an image,
a CCD ( coarseness,
contrast,
and directionality) texture feature representation has
developed in [T78,FFN93].
Coarseness is a measure of granularity of the texture, i.e. fine vs
coarse.
Contrast represents the distribution of luminance of the image and is
defined as
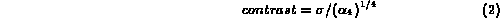
where 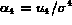 . Here
. Here  and
and 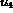 are
the standard deviation and the fourth
central moment of the luminance, respectively.
Directionality is a measure of how ``directional'' the
image is.
Using the above definitions of CCD, texture
is represented as a set of three numbers.
A problem with the above described CCD features is that
it is sensitive to noise. We have developed and implemented
an enhanced version of CCD by using histogram-base
features [MCO97].
Experimental results show that our enhanced version
is much more robust and accurate than the original definition of
CCD [MCO97].
are
the standard deviation and the fourth
central moment of the luminance, respectively.
Directionality is a measure of how ``directional'' the
image is.
Using the above definitions of CCD, texture
is represented as a set of three numbers.
A problem with the above described CCD features is that
it is sensitive to noise. We have developed and implemented
an enhanced version of CCD by using histogram-base
features [MCO97].
Experimental results show that our enhanced version
is much more robust and accurate than the original definition of
CCD [MCO97].
Shape Features: Shape of an object in an image is represented by its boundary. A technique for storing the boundary of an object using modified Fourier descriptor (MFD) is described in [RSH96]. To measure similarity between two shapes, the Euclidean distance between two shape features can be used. In [RSH96], however, we proposed a standard deviation based similarity measure that performs significantly better compared to the simple Euclidean distance. The proposed representation and similarity measure provide invariance to translation, rotation, and scaling of shapes, as well as the starting point used in defining the boundary sequence.
Layout Features:
The features discussed so far
only describe the global properties of the image. Besides these global
properties, MARS also supports features that describe the layout of
color and texture in an image.
To extract the
layout features, the whole image is first split into 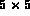 sub-images. Then color and texture features are extracted from each
sub-image and stored in the database.
For color layout, a two-dimensional HS histogram is constructed
for each sub-image, similar to the procedure described earlier.
sub-images. Then color and texture features are extracted from each
sub-image and stored in the database.
For color layout, a two-dimensional HS histogram is constructed
for each sub-image, similar to the procedure described earlier.
Since the enhanced CCD representation uses a histogram based measure, it is not suitable for texture layout. This is because the small sub-images may not produce good histograms. Instead, a wavelet-based representation is used, in which the mean and the standard deviation at 10 sub bands are used to represent the texture of each sub-image.
The Euclidean distance is used to compute the texture similarity distance for the corresponding sub-images. A weighted sum is then used to form the texture layout distance.
This section will discuss how to support the Boolean query based on the
simple feature distances.
MARS supports two mechanisms for generating the ranking of Boolean queries
-- the first
is based on the fuzzy interpretation of the distance and the
second is based on a probabilistic interpretation.
In the discussion below, we will use the following
notation. Images in the collection
are represented as 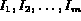 .
Features over the images are represented as
.
Features over the images are represented as 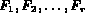 , where
, where
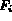 is used to represent both
the name of the feature as well as the domain of values that the feature can
take. For example, say
is used to represent both
the name of the feature as well as the domain of values that the feature can
take. For example, say 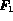 is the color feature which is
represented in the database using an HS histogram. In that case,
is the color feature which is
represented in the database using an HS histogram. In that case,
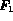 is also used to represent the set of all the color histograms.
A query is a Boolean expression
is also used to represent the set of all the color histograms.
A query is a Boolean expression 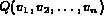 , where
, where
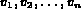 are variables. Each variable
are variables. Each variable 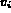 takes its
value from some domain
takes its
value from some domain 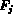 .
For example, a query,
.
For example, a query,
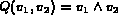 may be a query where
may be a query where 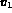 has a value
equal to the color histogram associated with image
has a value
equal to the color histogram associated with image 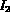 and
and 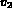 has
a value of the texture feature associated with
has
a value of the texture feature associated with 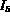 .
The query Q then represents a desire to retrieve images whose
color matches that of image
.
The query Q then represents a desire to retrieve images whose
color matches that of image 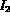 and whose texture matches that of
image
and whose texture matches that of
image 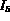 .
.
Let 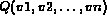 be a query and I be an image.
In the fuzzy retrieval model, a query variable
be a query and I be an image.
In the fuzzy retrieval model, a query variable 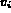 is considered
to be a fuzzy set of images I such that the distance between the
variable
is considered
to be a fuzzy set of images I such that the distance between the
variable 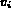 and the corresponding feature in I is used to compute
the degree of membership of I in the fuzzy set. That is:
and the corresponding feature in I is used to compute
the degree of membership of I in the fuzzy set. That is:
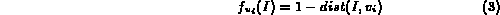
where 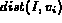 represents the distance measure between
represents the distance measure between 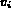 and the corresponding feature in the image I.
With the above interpretation of the distance measure between the
image feature and the feature specified in the query,
a Boolean query Q is interpreted as an expression in fuzzy logic
and fuzzy set theory is used to
compute the degree of membership of an image to the fuzzy set
represented by the query Q. Specifically, the degree of membership
for a query Q is computed as follows:
and the corresponding feature in the image I.
With the above interpretation of the distance measure between the
image feature and the feature specified in the query,
a Boolean query Q is interpreted as an expression in fuzzy logic
and fuzzy set theory is used to
compute the degree of membership of an image to the fuzzy set
represented by the query Q. Specifically, the degree of membership
for a query Q is computed as follows:
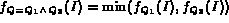

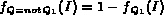
Consider for example a queryQ:
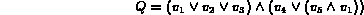
The membership of an image I in the fuzzy set corresponding to Q can be determined as follows:
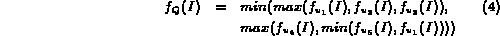
The value 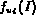 in the above formula is determined using
the equation (3).
Once the membership value of the image in the fuzzy set associated with
the query have been determined, these values
are used to rank the images, where a higher value of
in the above formula is determined using
the equation (3).
Once the membership value of the image in the fuzzy set associated with
the query have been determined, these values
are used to rank the images, where a higher value of 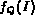 represents
a better match of the image I to the query Q.
We refer to the fuzzy Boolean model as model F1.
represents
a better match of the image I to the query Q.
We refer to the fuzzy Boolean model as model F1.
Let 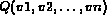 be a query and I be an image.
In the probabilistic Boolean model, the distance
be a query and I be an image.
In the probabilistic Boolean model, the distance
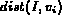 between the query variable
between the query variable 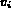 and the corresponding
feature in the image is used to compute the
probability of the image I matching the query variable
and the corresponding
feature in the image is used to compute the
probability of the image I matching the query variable
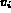 , denoted by
, denoted by 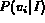 .
These probability measures are then used to compute
the probability that
I satisfies the query
.
These probability measures are then used to compute
the probability that
I satisfies the query 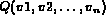 (denoted by
(denoted by 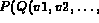
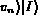 ) which is in turn used to
rank the images. To be able to compute
) which is in turn used to
rank the images. To be able to compute
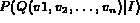 , an assumption of feature independence
is made. That is, we assume that for all variables
, an assumption of feature independence
is made. That is, we assume that for all variables 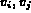 such
that the domain of
such
that the domain of 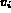 is not the same as the domain of
is not the same as the domain of 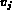 , the
following holds:
, the
following holds:
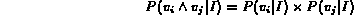
Before the probabilistic Boolean model can be used, however, we need to map the distance measure between a query variable and the image into a measure of probability that the image matches the query variable. There are many ways in which such a mapping can be achieved. Three such mechanisms (depicted in Figure 1) implemented in MARS are described below.
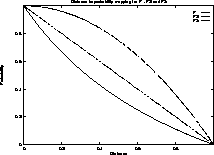
Figure 1: Distance to probability transformation functions.
It is easy to verify that for each of the above interpretations of
probability, the range of 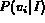 is [0, 1]. In
addition, when
is [0, 1]. In
addition, when 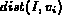 equals 0 (best match),
equals 0 (best match), 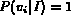 ; when
; when
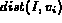 equals 1 (worst match),
equals 1 (worst match), 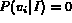 . Also,
. Also,
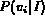 is a monotonic decreasing function of
is a monotonic decreasing function of 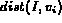 , which fits the
physical meanings of
, which fits the
physical meanings of 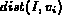 and
and 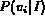 .
.
The choice of the mapping has an impact on the image ranking and as a result on the retrieval performance. We will discuss this further in the section on experimental results. We will refer to the three different probabilistic Boolean models resulting from the above equations as models P1, P2, and P3 respectively.
Once distance between image and the query variable has been converted
to a probability measure,
we next need to estimate the probability that the image
satisfies the Boolean query 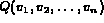 , denoted by
, denoted by
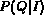 . If
Q is a disjunction
. If
Q is a disjunction 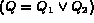 , following the laws of
probability,
, following the laws of
probability, 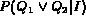 can be estimated as follows:
can be estimated as follows:
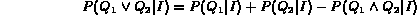
Since all probabilities are conditioned on the image I, we will omit this
for brevity from now on.
Similarly, 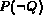 can be computed as follows:
can be computed as follows:

To compute conjunction queries, i.e. 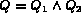 it is
desirable that
it is
desirable that 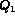 and
and 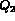 are independent so that
are independent so that 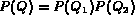 .
However even though features
are independent, the sub queries
.
However even though features
are independent, the sub queries 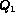 and
and 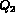 may not be independent.
To see this consider for
example, a query
may not be independent.
To see this consider for
example, a query 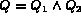 , where
, where
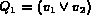 and
and 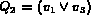 . In such a case
since
. In such a case
since 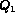 and
and 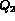 are not independent,
are not independent,
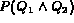 cannot be replaced by the product of
cannot be replaced by the product of
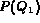 and
and 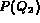 .
.
The above motivates us to convert the query into a
disjunctive normal form (DNF) in which a query is represented as
a disjunction of conjuncts .
Once the query has been converted to a DNF expression, we can compute
the probability of an image satisfying the query based on the
probability that the image satisfies query feature variables.
We illustrate how computation is done using an example.
Consider a query
.
Once the query has been converted to a DNF expression, we can compute
the probability of an image satisfying the query based on the
probability that the image satisfies query feature variables.
We illustrate how computation is done using an example.
Consider a query
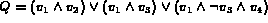 .
.
: Example Derivation
In the derivation shown in figure 2,
we have made the assumption that
each pair of variables 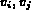 are over independent features.
For example,
are over independent features.
For example, 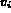 may be a color histogram and
may be a color histogram and 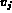 may be the
shape feature. Notice that, in general, the two variables
may be over the same feature space. For example, in a query
may be the
shape feature. Notice that, in general, the two variables
may be over the same feature space. For example, in a query
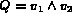 ,
, 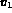 and
and 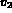 may correspond to
two color histograms. Our retrieval results (see Section 5) show
that even if these variables are considered as independent, the
resulting retrieval performance is quite good.
Developing a feature
dependence model and incorporating it in the
system may improve retrieval performance further and is an
important extension to our current work.
may correspond to
two color histograms. Our retrieval results (see Section 5) show
that even if these variables are considered as independent, the
resulting retrieval performance is quite good.
Developing a feature
dependence model and incorporating it in the
system may improve retrieval performance further and is an
important extension to our current work.
While the above developed Boolean retrieval models provide a mechanism for ranking the given images based on the query, for the approach to be useful, techniques must be developed to retrieve the best N matches efficiently without having to rank each image. Such a technique consists of two steps:
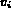 in the query.
in the query.
The images can be efficiently retrieved ranked based on a single feature
by maintaining an index based on that feature. Since all features in MARS
are represented as feature vectors with multiple feature elements,
retrieval of images ranked based on a single feature requires search using
the values of all the elements in the feature vector.
For example, the color feature in MARS is a 64-element vector
(8  8 histogram).
An alternative is to use several single-attribute indexes,
one for each feature element of the feature vector.
This is extremely inefficient in terms of the number of I/O
accesses needed for the search.
The other alternative is to use one or more of the existing
multidimensional data structures [N
8 histogram).
An alternative is to use several single-attribute indexes,
one for each feature element of the feature vector.
This is extremely inefficient in terms of the number of I/O
accesses needed for the search.
The other alternative is to use one or more of the existing
multidimensional data structures [N 84,Gut84,D.90].
However, these data structures do not scale
to the high dimensionality of the feature vectors used in MARS.
Moreover, since these data structures can only be used to index
Euclidean feature vectors, they cannot be used for features
defined over non-Euclidean distance measures
(e.g. color histograms for which the intersection distance metric is used).
Instead MARS uses an incremental clustering approach described in
[RCM
84,Gut84,D.90].
However, these data structures do not scale
to the high dimensionality of the feature vectors used in MARS.
Moreover, since these data structures can only be used to index
Euclidean feature vectors, they cannot be used for features
defined over non-Euclidean distance measures
(e.g. color histograms for which the intersection distance metric is used).
Instead MARS uses an incremental clustering approach described in
[RCM 97].
97].
Once efficient ranked retrieval based on a single feature
has been achieved, the ranked lists are normalized
and then the normalized ranked lists are merged into a ranked
set of images corresponding to a query.
The normalization process used in MARS is described in the
following section. To merge the normalized ranked lists,
a query 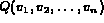 is viewed as a query tree whose leaves correspond to single
feature variable queries. Internal nodes
of the tree correspond to
the Boolean operators. Specifically, nodes are of either of the
three forms:
is viewed as a query tree whose leaves correspond to single
feature variable queries. Internal nodes
of the tree correspond to
the Boolean operators. Specifically, nodes are of either of the
three forms: 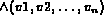 which is a conjunction
of positive literal;
which is a conjunction
of positive literal;
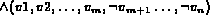 , which is
a conjunction consisting of both positive and negative literals; and
, which is
a conjunction consisting of both positive and negative literals; and
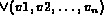 which is a disjunction of positive literals.
The query tree is evaluated as a pipeline from the leaf to the root.
Each node in the tree provides to its parent a ranked list of images,
where the ranking corresponds to
the degree of membership (in the fuzzy model), or the measure of
probability (in the probabilistic model). For example,
in the fuzzy model, a node n in a tree provides to its parent a
ranked list
which is a disjunction of positive literals.
The query tree is evaluated as a pipeline from the leaf to the root.
Each node in the tree provides to its parent a ranked list of images,
where the ranking corresponds to
the degree of membership (in the fuzzy model), or the measure of
probability (in the probabilistic model). For example,
in the fuzzy model, a node n in a tree provides to its parent a
ranked list  , where
, where
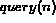 corresponds to the query associated with the node n.
corresponds to the query associated with the node n.
The algorithms used to combine the ranked lists of images from the child to generate a list for parents depend upon the retrieval model used. The algorithms for the fuzzy model are discussed in the Appendix. The corresponding algorithms for the probabilistic model are more complex and not included due to space restrictions. They can be found in [OMR+97].
The normalization process serves two purposes:
This normalization process is only needed for vector based feature representation, as in the case of wavelet texture feature representation. In other cases, such as color histogram intersection, where all the feature elements are defined over the same physical domain, no intra-feature normalization is needed.
For the vector based feature representation,
let 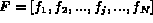 be the feature vector,
where N is the
number of feature elements in the feature vector and
be the feature vector,
where N is the
number of feature elements in the feature vector and
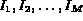 be the images.
For image
be the images.
For image 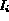 , we refer the corresponding feature F as
, we refer the corresponding feature F as
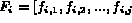
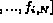 .
.
Since there are M images in the database, we can form a 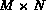 feature
matrix
feature
matrix
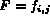 ,
where
,
where 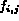 is the jth feature element in feature vector
is the jth feature element in feature vector 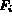 .
Now, each column of F is a length-M sequence of the jth feature element,
represented as
.
Now, each column of F is a length-M sequence of the jth feature element,
represented as 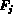 .
Our goal is to normalize the entries in each column to
the same range so as to ensure that each individual feature element
receives equal weight in determining the Euclidean distance between
the two vectors. One way of
normalizing the sequence
.
Our goal is to normalize the entries in each column to
the same range so as to ensure that each individual feature element
receives equal weight in determining the Euclidean distance between
the two vectors. One way of
normalizing the sequence 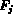 is to find the maximum and minimum values of
is to find the maximum and minimum values of
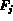 and normalize the sequence to [0, 1] as follows:
and normalize the sequence to [0, 1] as follows:
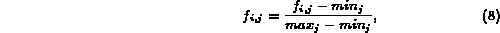
where 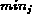 and
and 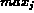 refer to the smallest and the biggest value of
refer to the smallest and the biggest value of
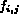 ,
, 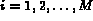 .
Although simple, this is not a desirable normalization.
Considering the sequence {1.0, 1.1, 1.2,
1.3, 100}, if we use (8) to normalize the sequence, most of the [0, 1]
range will be taken away by a single element 100,
and most of the useful information in
{1.0, 1.1, 1.2, 1.3} will be warped into a very narrow range.
.
Although simple, this is not a desirable normalization.
Considering the sequence {1.0, 1.1, 1.2,
1.3, 100}, if we use (8) to normalize the sequence, most of the [0, 1]
range will be taken away by a single element 100,
and most of the useful information in
{1.0, 1.1, 1.2, 1.3} will be warped into a very narrow range.
A better approach is to use the Gaussian normalization.
Assuming
the feature sequence 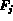 to be a Gaussian sequence, we compute the mean
to be a Gaussian sequence, we compute the mean
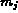 and standard deviation
and standard deviation 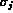 of the sequence. We then normalize
the original sequence to a N(0,1) sequence as follows:
of the sequence. We then normalize
the original sequence to a N(0,1) sequence as follows:
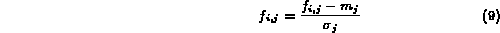
It is easy to prove that
after the normalization according to (9), the probability
of a feature element
value being in the range of [-1, 1]
is 68%. If we use 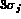 in the
denominator, according to the 3-
in the
denominator, according to the 3- rule, the probability
of a feature element value being
in the range of [-1, 1] is approximately
99%. In practice, we can consider all of the feature element
values are within the range of [-1,1] by mapping the out-of-range
values to either -1 or 1.
The advantage of this
normalization process over (8) is that the presence of a few
abnormally large or small values does not bias the importance of the
feature element in computing the distance between feature vectors.
rule, the probability
of a feature element value being
in the range of [-1, 1] is approximately
99%. In practice, we can consider all of the feature element
values are within the range of [-1,1] by mapping the out-of-range
values to either -1 or 1.
The advantage of this
normalization process over (8) is that the presence of a few
abnormally large or small values does not bias the importance of the
feature element in computing the distance between feature vectors.
Intra-feature normalization ensures equal emphasis of each feature element within a feature. On the other hand, inter-feature normalization ensures equal emphasis of each feature within a composite query.
The feature representations used in MARS are of various forms, such as vector based (wavelet texture representation), histogram based (histogram color representation), irregular (MFD shape representation).
To map the distance computations of the heterogeneous features
to the same scale and into the range [0,1] the following inter-feature
normalization process is used for each feature 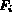 .
.
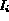 and
and 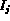 , compute the similarity
distance
, compute the similarity
distance 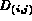 between them:
between them:
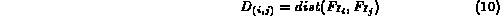

where 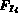 and
and 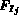 are the feature representations of images
are the feature representations of images
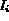 and
and 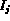 .
.
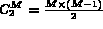 possible distance values between any pair of images,
treat them
as a value sequence and find the mean m and standard
deviation
possible distance values between any pair of images,
treat them
as a value sequence and find the mean m and standard
deviation  of the sequence. Store m and
of the sequence. Store m and  in the database to be used in later normalization.
in the database to be used in later normalization.
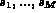 denote the raw similarity values.
denote the raw similarity values.

As explained in the intra-feature normalization section, this
Gaussian normalization will ensure 99% of 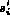 to
be within the range of [-1,1]. An additional
shift will guarantee that 99% of similarity values are
within [0,1]:
to
be within the range of [-1,1]. An additional
shift will guarantee that 99% of similarity values are
within [0,1]:

After this shift, in practice, we can consider all the values are within the range of [0,1], since an image whose distance from the query is greater than 1 is very dissimilar and can be considered to be at a distance of 1 without affecting retrieval.
After the intra- and inter-feature normalization processes discussed above, the feature elements within a feature as well as the features within a composite query are of equal weights. This objective equality allows us to further associate subjective unequal intra- and inter-feature weights for a particular query.
Inter-feature weights associated with the composite query reflect the user's different emphasis of the atomic feature in the composite query. For example, for a composite query based on color and texture, a user may put the weight for color equals 90% and weight for texture equals 10%. The support of different inter-feature weights enables the user to specify his/her information need more precisely.
Intra-feature weights associated with each feature vector reflect the different contributions of the feature elements to the feature vector. For example, in the wavelet texture representation, we know that the mean of a sub-band may be corrupted by the lighting condition, while the standard deviation of a sub-band is independent of the lighting condition. Therefore the user may want to put more weight on the standard deviation feature element, and less weight on the mean feature element. The support of the different intra-feature weights enables the system to have more reliable feature representation and thus better retrieval performance.
In MARS, we have explored many techniques to associate subjective weights with feature elements and feature vectors. Associating subjective weights improves the retrieval performance considerably. Due to page limitations we do not discuss this any further. Instead we refer the readers to [RHMO97b,RHMO97a].
For our experiments we used a collection of images of ancient African artifacts from the Fowler Museum of Cultural History. We used a total of 286 images of such artifacts. A sample of our collection is shown as the result of a query in figure 3.
: Screen shot of the query ``texture or shape'' with a stool image
as parameter
To demonstrate the retrieval quality of our system, we chose 13 typical conceptual queries, three examples of which are ``all stools'', ``stone masks'' or ``golden pots''. Sample images satisfying these three concept queries are shown in figure 4.
Figure 4: Three sample images used in conjunction with known
relevant sets to evaluate precision and recall
To determine the relevant answer sets for each of the conceptual queries, we browsed through the collection and marked those images relevant to a concept. The concept queries were then mapped into a Boolean formulation that best represents them (e.g. stone masks are expressed as `texture=image X and shape=image Y').
As in the text based retrieval systems, the retrieval performance is defined based on precision and recall [SM83,CCH92].

Perfect precision (100%) means that all retrieved images are relevant.

Perfect recall (100%) can be obtained by retrieving the entire collection, but the precision will be poor.
We have conducted experiments in which we calculate precision at various levels of recall. These results are reported in figure 5.
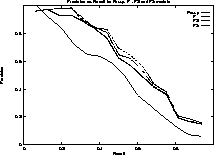
Figure 5: Precision for various levels of recall averaged over 13 queries
As we can see from the figure, the probability models consistently outperform the fuzzy model at equal recall or precision points. An interpretation of this is that the fuzzy model includes only partial information. For and (or) queries, the fuzzy model uses the min (max) operation that selects an image based on the worst (best) degree of membership in both operand sets. This ignores any contribution of the other operand set in computing the final degree of membership of an image. The probability model instead combines the information provided by both terms in a better way. This allows for an improved ranking as more information about an image is captured.
We can also see that P1 is the best among the three probability models.
This relates to figure 1 where P1 < P2 < P3 at
the same distance.
Model P1 has a sharper drop in probability for distance less than 0.414.
This has the effect of
``warping'' space close to the optimum match (Pr = 1) which results
in slight ranking differences in the and and or operations.
By this effect, good matches are drawn closer by a larger factor
which has the effect of increasing precision.
P1 gives
more importance to images ranking good in any of the operand sets while
models P2 and P3 give progressively less importance to good rankings,
trying to equate them to worse rankings in the hope that the combination
might be better.
A faster decreasing function will negatively impact recall.
In the limiting case (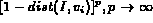 )
precision will be 1, but recall very low since even small distance reductions
between a feature and the query feature will result in a large probability
drop. As a result, similar images (unless they match perfectly) would rank
lower and thus not be returned.
)
precision will be 1, but recall very low since even small distance reductions
between a feature and the query feature will result in a large probability
drop. As a result, similar images (unless they match perfectly) would rank
lower and thus not be returned.
Content-based retrieval of images is an active area of research being
pursued independently by many research teams.
Similar to MARS, most existing content-based image retrieval systems also
extract low-level image features like
color, texture, shape, and structure
[FFN93,T78,MCO97,F95,M88,MM95,PPS94,SC94].
However, compared to MARS the retrieval techniques supported in some of
these systems are quite primitive.
Many of these systems support queries only on single
features separately.
Certain other systems allow queries over
multiple feature sets by associating a degree of tolerance
with each feature. An image is deemed similar to the query
if it is within the specified tolerance on all the query features.
As discussed in section 1.2,
this approach has many drawbacks.
Some commercial systems have been developed.
QBIC [F95],
standing for Query By Image Content, is the first commercial
content-based Image Retrieval system. Its system framework and
techniques had profound effects on later Image Retrieval systems.
QBIC supports queries based on example images, user-constructed
sketches and drawings and selected color and texture patterns, etc.
The color features
used in QBIC are the average (R,G,B), (Y,i,q),(L,a,b) and MTM
(Mathematical Transform to Munsell) coordinates, and a k element Color
Histogram. Its texture feature is an improved version of
the Tamura texture representation [T78], i.e. combinations of
coarseness, contrast and directionality. Its shape
feature consists of shape area, circularity, eccentricity, major axis
orientation and a set of algebraic moments invariants.
QBIC is one of the few systems which take into
account high dimensional feature indexing.
In its indexing subsystem, the KL transform is first used to
perform dimension reduction and then  -tree is used as the
multi-dimensional indexing structure.
-tree is used as the
multi-dimensional indexing structure.
Virage is a content-based image search engine developed at Virage Inc.
Similar to QBIC, Virage [BFG]
supports visual queries based on color,
composition (color layout), texture, and structure (object boundary
information). But Virage goes one step further than QBIC. It also
supports arbitrary combinations of the above four atomic queries.
Users can adjust the weights associated with the atomic features
according to their own emphasis. In [BFG], Jeffrey et
al. further proposed an open framework for image management. They
classified the visual features (``primitive'') as general (such as
color,
shape, or texture) and domain specific (face recognition, cancer cell
detection, etc.). Various useful ``primitives'' can be added to the
open structure depending on the domain requirements. To go beyond the
query-by-example mode, Gupta and Jain proposed a nine-component
query language framework in [GJ97].
Photobook [PPS94] is a set of interactive tools for browsing and searching images developed at the MIT Media Lab. Photobook consists of three sub-books, from which shape, texture, and face features are extracted respectively. Users can then query based on corresponding features in each of the three sub-books. In its more recent version of Photobook, FourEyes, Picard et al. proposed to include human in the image annotation and retrieval loop [MP96]. The motivation of this was based on the observation that there was no single feature which can best model images from each and every domain. Furthermore, human perception is subjective. They proposed a ``society of models'' approach to incorporate the human factor. Experimental results show that this approach is very effective in interactive image annotation.
In [JV96] the authors propose an image retrieval system based on color and shape.
Their color measure is based on the RGB color space and euclidean and histogram intersection measures are used. For shape, they use a polygonal description that is resilient to scaling, translation and rotation.
The proposed integration uses a weighted sum of shape and color to arrive at the final result. They address high dimensional feature indexing with a clustering approach, where clusters are build upon database creation time.
To date, no systematic approach to answering content based queries based on image features has emerged. To address this challenge, similar to the approaches taken in information retrieval system, the approach we have taken in developing MARS is to support an ``intelligent retrieval'' model using which a user can specify their information need to the image database and the database provides a ranked retrieval of images to user's request. The retrieval model supported is a variation of the Boolean model based on probabilistic and fuzzy interpretation of distances between the image and the query.
Recently, in parallel to our work, the problem of processing boolean queries over multimedia repositories has also been studied in [Fag96] and [CG96]. These approaches have, however, restricted themselves to a boolean model based on a fuzzy interpretation of boolean operators. Our experimental results illustrate that the probabilistic model outperforms the fuzzy model in terms of retrieval performance (see figure 5). Furthermore, the query evaluation approach used in MARS differs significantly from the approaches developed in [Fag96,CG96]. As will become clear in the appendix, MARS follows a demand-driven data flow approach [Gra96]; i.e., data items are never produced before they are needed. So the wait in a temporary file or buffer between operators in the query tree for each item is minimized. This model is efficient in its time-space-product memory costs [Gra96]. In this model, the operators are implemented as iterators which can be effectively combined with parallel query processing. On the other hand, the strategy presented in [Fag96] requires intermediate storage of data items at internal nodes of the query tree to evaluate the best N answers. This is also true for the approach followed in [CG96].
To address the emerging needs of applications that require
access to and retrieval of multimedia objects,
we are developing the Multimedia Analysis and
Retrieval System (MARS) in our group at the
University of Illinois [MCO97].
In this paper, we described the retrieval subsystem of MARS and its
support for content-based queries over image databases.
To support content-based retrieval, in MARS many visual
features are extracted from images-- color, texture, shape, color and texture layout.
Information retrieval (IR) techniques, modified to work over visual features,
are then used to map user's queries to a collection of relevant images.
Specifically, extended boolean models based on a probabilistic and fuzzy
interpretation of boolean operators are used to support ranked
retrieval. Our results show that using IR techniques
for content-based retrieval in image databases is a promising approach.
The work reported in this paper is being extended in many important directions. In our current system, we have concentrated on adapting the boolean retrieval model for content-based retrieval of images. Many other retrieval models that have a better retrieval performance compared to the boolean approach have been developed in the IR literature for textual databases [SM83,CCH92,VR79]. We are currently exploring how these models can be adapted for content-based image retrieval. Furthermore, our current work has concentrated on image databases. We are also generalizing our approach to content-based retrieval in multimedia databases. Finally, we are also exploring the use of relevance feedback techniques in our extended boolean model.
This work was supported in part by the Army Research Laboratory under Cooperative Agreement No. DAAL01-96-2-0003; in part by NSF/DARPA/NASA Digital Library Initiative Program under Cooperative Agreement No. 94-11318; in part by NSF CISE Research Infrastructure Grant CDA-9624396. Yong Rui is supported in part by CSE, College of Eng. UIUC. Michael Ortega is supported in part by CONACYT grant 89061. The example images used in this article are used with permission from the Fowler Museum of Cultural History at the University of California--Los Angeles. These images were part of an image database delivery project called the Museum Educational Site Licensing Project (MESL), sponsored by the Getty Information Institute. This goal of the two-year MESL project was to test the licensing and delivery of digital images and meta data from seven U. S. museums to seven U. S. universities. The University of Illinois was selected as a participant in the MESL project.
95
93
88
97
84
 97
97
97
78
In this appendix, we present the algorithms used to compute the
nodes in the query tree in the case of the fuzzy Boolean retrieval
model.
For simplicity we restrict ourselves to compute only binary nodes.
That is, we assume that the query node Q has exactly two children,
A, and B. Algorithms are presented for the following three
cases: 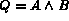 ,
, 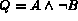 and
and
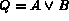 . Notice that we do not present an algorithm
for only an unguarded negation (i.e.,
. Notice that we do not present an algorithm
for only an unguarded negation (i.e., 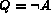 ) or a negation in the
disjunction (i.e.,
) or a negation in the
disjunction (i.e., 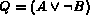 ). Presence of an unguarded negation
or negation in a disjunction
does not make much intuitive sense. Typically, a very large number of images
will satisfy the query and if such a negation is present in the
query, it is best to rank each image and sort the answer set based on this
ranking. We therefore only consider a restricted notion of negation when
it appears within a conjunctive query.
). Presence of an unguarded negation
or negation in a disjunction
does not make much intuitive sense. Typically, a very large number of images
will satisfy the query and if such a negation is present in the
query, it is best to rank each image and sort the answer set based on this
ranking. We therefore only consider a restricted notion of negation when
it appears within a conjunctive query.
In describing the algorithms the following notation is used.
 )
and a degree of membership (
)
and a degree of membership ( ).
The key identifies the image and the degree of membership
describes the match between the query feature and the database entries.
).
The key identifies the image and the degree of membership
describes the match between the query feature and the database entries.
 ,
, 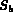 and
and  . Initially each of these sets are empty.
The query node Q extracts images from the child streams (that is,
A and B) and may buffer them into
. Initially each of these sets are empty.
The query node Q extracts images from the child streams (that is,
A and B) and may buffer them into 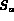 and
and 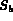 .
The set
.
The set  acts as a buffer of the images for the
query node Q.
Once a query node Q is able to estimate the degree of
membership of image I for Q (that is,
acts as a buffer of the images for the
query node Q.
Once a query node Q is able to estimate the degree of
membership of image I for Q (that is, 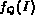 ), it
places I in
), it
places I in  . Thus,
. Thus, 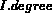 refers to the degree of
membership of I according to Q, where
refers to the degree of
membership of I according to Q, where 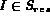 .
.
In describing the algorithms below we omit some critical error and boundary checking for clarity purposes, which have been addressed in the implementation.
The following algorithm computes the set of images ranked
on their degree of membership to the query 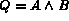 ,
given input streams A and B which are ranked based on the
degree of membership of images in A and B.
In the algorithm, at each stage,
the best image out of the sources A and B is chosen and
added to a set of images
,
given input streams A and B which are ranked based on the
degree of membership of images in A and B.
In the algorithm, at each stage,
the best image out of the sources A and B is chosen and
added to a set of images 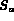 and
and 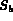 which function as
buffers of images already observed from the corresponding stream.
When an image is found that was already observed in the other
stream, the loop is terminated since this is the next best image
according to the query node Q.
The resulting image is returned (that is, placed in the set
which function as
buffers of images already observed from the corresponding stream.
When an image is found that was already observed in the other
stream, the loop is terminated since this is the next best image
according to the query node Q.
The resulting image is returned (that is, placed in the set  )
with the degree equal to the minimum degree of the image
in both streams.
)
with the degree equal to the minimum degree of the image
in both streams.
Algorithm GetNextAnd_Fuzzy(A , B )
;returns: next best image in A and B \
while (TRUE)
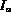 = Peek (A ),
= Peek (A ), 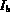 = Peek (B )
= Peek (B )
if 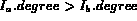 then
then
&nb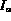 = GetNext(A )
= GetNext(A )
&nb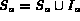
&nbif  then ;image already seen in B
then ;image already seen in B
&nb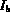 = image
= image 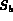 [
[ ]
]
&nbexit loop
&nbend if
else
if 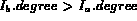 then
then
&nb = GetNext(B )
= GetNext(B )
&nb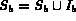
&nbif  then ;image already seen in A
then ;image already seen in A
&nb = image
= image  [
[ ]
]
&nbexit loop
&nbend if
end if
end while
; reached upon finding a common image in 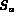 and
and 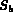
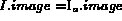
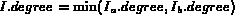
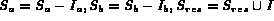
return I
We next develop the algorithm for computing the query 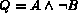 .
The algorithm is different
compared to the one developed for the conjunctive query with no negative
sub query. Unlike the algorithm discussed earlier, only the stream for
the node A is used in computing the degree of membership of images
according to
.
The algorithm is different
compared to the one developed for the conjunctive query with no negative
sub query. Unlike the algorithm discussed earlier, only the stream for
the node A is used in computing the degree of membership of images
according to 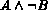 . Images are retrieved from the
input stream A in ranked order.
. Images are retrieved from the
input stream A in ranked order.
For a given image I its degree
of membership in the set associated with 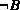 is evaluated using the
following function:
is evaluated using the
following function:
Probe(I, query): the Probe function returns the degree of membership of the image identified byin the fuzzy set associated with the query.
Let I be the image in  with the highest degree according to
Q and let
with the highest degree according to
Q and let 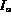 be the next best image in rank order in stream A.
An image is the next best match if either of the two conditions hold:
be the next best image in rank order in stream A.
An image is the next best match if either of the two conditions hold:
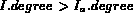 then I is the next best match according
to Q since all other images to follow will have the degree of membership
according to Q less than
then I is the next best match according
to Q since all other images to follow will have the degree of membership
according to Q less than 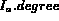 .
.
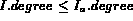 but
but 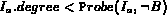 then
then 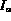 is the next best match according to Q since the membership of
is the next best match according to Q since the membership of
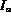 is better than all the images already in
is better than all the images already in  , and is also
higher than all other images that will be produced in the future.
, and is also
higher than all other images that will be produced in the future.
To find the next best match according to Q, As stream is traversed until one of the two conditions become true.
Algorithm GetNextAnd_Not_Fuzzy(A , B )
;returns: next best image in A and not B \
while (TRUE)
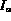 = Peek (A )
= Peek (A )
if 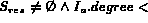 MaximumDegree(
MaximumDegree( ) then
) then
&nbI = image from  with maximum degree
with maximum degree
&nb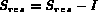
&nbexit loop
else
&nb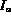 = GetNext(A ) ; consume from A
= GetNext(A ) ; consume from A
&nb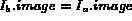
&nb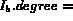 Probe(
Probe(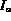 ,
, 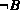 )
)
&nbif 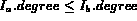 then
then
&nb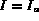
&nbexit loop
&nbelse
&nb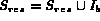
&nbend if
end if
end while
return I
The following algorithm computes the set of images ranked
on their degree of membership to the query 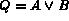 ,
given input streams A and B which are ranked based on the
degree of membership of images in A and B.
The algorithm essentially consists of a merge
but makes sure that an image that was already retrieved
is ignored. This accomplishes the desired max behavior of
the degree function associated with the disjunction in the fuzzy model.
,
given input streams A and B which are ranked based on the
degree of membership of images in A and B.
The algorithm essentially consists of a merge
but makes sure that an image that was already retrieved
is ignored. This accomplishes the desired max behavior of
the degree function associated with the disjunction in the fuzzy model.
Algorithm GetNextOr_Fuzzy(A , B )
;returns: next best image in A or B \
flag = TRUE
while (flag)
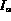 = Peek (A ),
= Peek (A ), 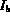 = Peek (B )
= Peek (B )
if 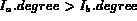 then
then
&nbI = GetNext(A )
else
&nbI = GetNext(B )
end if
flag = FALSE
if 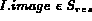 then
then
&nbflag = TRUE
end if
end while
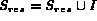
return I