Figure 1: Service Slots of Fixed-Stretch
November 8-14, 1997
Crowne Plaza Hotel, Seattle, USA
Interactive multimedia applications require fast response time. Traditional disk scheduling schemes can incur high latencies, and caching data in memory to reduce latency is usually not feasible, especially if fast-scans need to be supported. In this study we propose a disk-based solution called BubbleUp. It significantly reduces the initial latency for new requests, as well as for fast-scan requests. The throughput of the scheme is comparable to that of traditional schemes, and it may even provide better throughput than mechanisms based on elevator disk scheduling. BubbleUp incurs a slight disk storage overhead, but we argue that through effective allocation, this cost can be minimized.
Postscript Version (347K)
In recent years substantial effort has been devoted to the design of video servers that meet the continuous real-time deadlines of many clients. Although progress has been made regarding the throughput of such servers, one of the major VCR-like functions, fast-scan (both forward and backward) has not received much attention. A fast-scan operation allows a viewer to jump to any segment of a playing video. A media server can support fast-scan in two ways. One, the media server provides thumb-nail pictures to allow the viewer to select a video sequence to jump to. Two, the server maintains a separate fast version of a clip [BGMJ94, ORS96]. When a viewer performs a fast-scan, the video server switches playback to the fast version and returns to the regular version when the operation ends.
One of the most critical performance requirement for a fast-scan operation is fast response time. For example, consider a video game in which at each step the player's actions determine what short video sequence to play next. Clearly, we do not want the player to have to wait a significant amount of time before each video scene starts. Another application that requires low latency is hypermedia documents, as found in the World Wide Web or a Digital Library. Here a user may examine a web page that contains links to a variety of other pages, some of which may be multimedia presentations. Even in movie-on-demand applications where a few minutes' delay before a new multi-hour movie starts may be acceptable, when the viewer decides to fast-scan, response time should be very low.
In this paper, we focus on minimizing a media server's latency, both for an initial request and for a fast-scan request of an ongoing presentation. We measure this initial latency as the time between the request arrival and the time when the data is available in the server's main memory. The initial latency depends how fast the disk arm can start transferring data for the request. For current disk scheduling algorithms the initial latency can be relatively high. For example, most media server designs use an elevator-like disk scheduling policy that we call Sweep in this paper [CLOT96, GKS95a, OBRS94, RW94a, Ste95, TPBG93]. The Sweep policy amortizes the latency of the disk among the requests it services to reduce the seek overhead. However, if a new request accesses a video segment on the disk that has just been passed by the disk arm, the request must wait until the disk arm finishes the current sweep and returns to the data segment in the next sweep. This worst initial latency can be tens of seconds depending on the data layout and the disk configuration [CGM97b, GKS95a, GKS95b]. To work around this problem, memory caching techniques have been suggested. However, if a viewer is allowed to fast-scan to any segment of the video, then the entire video must be kept in memory, something that is typically too expensive.
In this study, we propose a resource management scheme, named BubbleUp, that minimizes the initial latency for servicing a newly arrived or a fast-scan request. BubbleUp works with a disk scheduling policy Fixed-Stretch that gives the disk arm the freedom to move to any disk cylinder before each IO. At first glance, giving the disk arm more freedom seems to be a bad idea, since the increased disk latency may degrade disk bandwidth. However, Fixed-Stretch also spaces out IO requests more regularly, and this significantly reduces the memory requirements. Thus, it turns out that the increase in the disk latency is compensated by the more efficient memory use, so overall throughput does not suffer (and may be better in some cases). In particular, our results will show that Fixed-Stretch supports comparable throughput to Sweep and another scheme called Group Sweeping Scheme (GSS) [YCK93]. Furthermore, the freedom to schedule IOs in any order makes possible our latency-reducing BubbleUp policy.
BubbleUp services requests in cycles, where each cycle is divided into equal duration slots. An ongoing presentation performs one IO per cycle, using up one of the slots in that cycle. The key to BubbleUp is that, as it schedules IOs into slots, it attempts to keep the next slot open to quickly handle an ``unexpected'' new request or fast-scan. This is analogous to how a person would schedule office work when expecting an important visitor. Here the slots are hours (say) and a cycle is a working day. Suppose that at 9am the visitor has not shown up, there is no work scheduled for 9am, but there is work scheduled for 10am. In this case it makes sense to perform the 10am work at 9am, thus making the 10am slot free to handle the visitor if he/she shows up then. In this way, the 9am free slot ``bubbles up'' to 10am. If the visitor still does not show up at 10am, we may move 11am work to 10am, bubbling up our open slot to 11am.
Of course, the situation is more complex with IO requests than with office work because the data read in one slot for a particular presentation is supposed to sustain that presentation until the same slot in the next cycle. If we move an IO from one slot to another within a cycle, BubbleUp must compensate by reading less or more data, or by changing the slot for this presentation in future cycles. The details as to how BubbleUp compensates and manages to give each presentation a steady stream of data are given in Section 3. Using these techniques, BubbleUp manages to keep slots open in the immediate future. This makes it possible to start a new presentation or a fast-scan very quickly (e.g., under a quarter of a second even with a heavy load), scheduling it into one of these open slots.
Supporting fast-scan operations presents a tradeoff with throughput. That is, a fast-scan operation may require two IOs for a single presentation in a cycle: one before the fast-scan request is made (this reads data from the ``old'' part of the video; some of this data will be discarded when playback of the ``new'' part starts), and one after the fast-scan request (to read in the new data). This implies that the extra IO bandwidth will not be available to service a brand new request that arrives. Thus, given some maximum number of IOs one wishes to support during a cycle, some of the capacity can be reserved for new requests and some for fast-scans of ongoing requests. In this paper we show that the memory required for a fast-scan operation is actually less than that required for a new request. Thus, by reducing the allowable number of new requests, one can actually support a larger number of fast-scans. As we will see, BubbleUp allows the media server to dynamically shift resources from supporting new requests to supporting fast-scans and vice versa without any transitional delay.
The rest of this paper consists of five sections. Section 2 describes the Fixed-Stretch disk scheduling scheme. Section 3 presents policy BubbleUp and examples. Sections 4 and 5 quantitatively analyze the performance of BubbleUp and compare it with other competing schemes. Finally, we offer our conclusions in Section 6.
We assume that the media server services requests in cycles. During a service cycle (time T), the server reads one segment of data for each of the requested streams, of which there can be at most Nlimit. We assume that each segment is stored contiguously on disk. The data for a stream is read (in a single IO) into a memory buffer for that stream, which must be adequate to sustain the stream until its next segment is read.
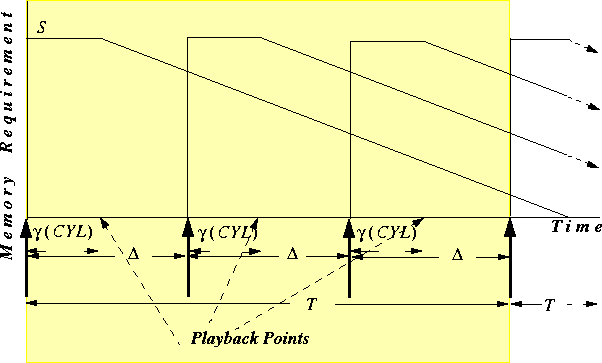
In a feasible system, the period T must be large enough so that in the worst case all necessary IOs can be performed. Thus, we must make T large enough to accommodate Nlimit seeks and transfer Nlimit segments. Fixed-Stretch achieves this by dividing a service cycle T into Nlimit equal service slots. Since the data on disk for the requests are not necessarily separated by equal distance, we must add time delays between IOs to make all service slots last for the same amount of time. For instance, if the seek distances for the IOs in a cycle are cyl.1, cyl.2,..., and cyl.n cylinders, and cyl.i is the maximum of these, then we must separate each IO by at least the time it takes to seek to and transfer this maximum i'th request. Since in the worst case the maximum cyl.i can be as large as the number of cylinders on the disk (CYL), Fixed-Stretch uses the worst possible seek distance CYL and rotational delay, together with a segment transfer time, as the universal IO separator, Delta, between any two IOs. We use gamma(CYL) to denote the worst case seek and rotational delay. If the disk transfer rate is TR, and each segment is S bytes long, then the segment transfer time is S/TR, so Delta = gamma(CYL) + S/TR.
The length of a period, T, will be Nlimit * Delta. Figure 1 presents an example where Nlimit = 3. The time on the horizontal axis is divided into service cycles each lasting T units. Each service cycle T (the shaded area) is equally divided into three service slots, each lasting Delta units (delimited by two thick up-arrows). The vertical axis in Figure 1 represents the amount of memory utilized by an individual stream.
Figure 1: Service Slots of Fixed-Stretch
Fixed-Stretch executes according to the following steps:
As its name suggests, the basic Fixed-Stretch scheme has two distinguishing features:
As mentioned in Section 1, Fixed-Stretch appears to be inefficient since it assumes the worse seek overhead between IOs. However, Fixed-Stretch uses memory very efficiently because of its very regular IO pattern, and this compensates for the poor seek overhead. In Section 4 we analyze the memory requirement of Fixed-Stretch and compare its performance with other disk scheduling policies (e.g., Sweep and GSS). We show that Fixed-Stretch achieves comparable throughput to the other schemes.
Policy BubbleUp builds upon Fixed-Stretch to minimize initial latency. We define initial latency to be the time between the arrival of a single new request (when the system is unsaturated) and the time when its first data segment becomes available in the server's memory. In computing the initial latency we do not take into account any time spent by a request waiting because the system is saturated (with Nlimit streams), as this time could be unbounded no matter what scheduling policy is in place. In other words, our focus is on evaluating the worst initial delay when both disk bandwidth and memory resources are available to service a newly arrived or a fast-scan request.
To simplify our discussion we temporarily assume that each media (i.e., all of its segments) is laid out contiguously on the disk. We relax this restriction in Section 3.5.
BubbleUp minimizes the initial latency by rescheduling the requests in Fixed-Stretch's service slots and by carefully managing the amount of data to retrieve for each request to prevent both data overflow and underflow. Table 1 summarizes the parameters defined so far, together with other parameters that will be introduced later.
| Parameter |
Description |
| DR | Data display rate, Mbps |
| TR | Data transfer rate, Mbps |
| CYL | Number of cylinders on disk |
| gamma(d) | Function computes seek overhead |
| S | Segment size, without fast-scans |
| S' | Segment size, with fast-scans |
| T | Service time for a round of requests |
| Delta | Service time for a service slot |
| Tseek | Total seek (and rotational) time |
| Ttransfer | Total data transfer time |
| N | Number of requests being serviced |
| n | Number of fast-scan operations has been serviced in this T |
| theta | The service slot where fast-scan initiated |
| Nlimit | System enforced limit on no. of requests |
| Mlimit | System enforced limit on no. of fast-scans |
| Ri | ith request |
| S.i | ith service slot |
| MemMin | Minimum memory requirement |
| Tlatency | Initial latency, seconds |
Table 1: Parameters
We use an example to illustrate how BubbleUp reduces initial latency. Assume that a media server supports up to three requests (Nlimit = 3) in a period T, as depicted in Figure 1. To service three requests in T, BubbleUp divides the period into three service slots, s.1, s.2, and s.3, each lasting time Delta.
Table 2 shows a sample execution for three requests R1, R2, R3. Each row of the table represents the execution for one service slot. The first column identify the time involved. Each slot instance is labeled as Delta i to remind us that its duration is Delta time units. Note that the first period or cycle has three slot instances (Delta 1, Delta 2, Delta 3). The first slot in a cycle, s.1, occurs in instances Delta 1, Delta 4, Delta 7, .... The last three columns in Table 2 show the requests that are currently scheduled for each slot in a cycle.
For our example, let us assume that request R1 arrives before Delta 1, R2 arrives during Delta 2, and R3 during Delta 4. When R1 arrives the system is empty and it is scheduled into the first slot s.1. The following steps then occur under policy BubbleUp:
| Time |
s.1 |
s.2 |
s.3 |
| Delta1 |
R1* |
- |
- |
| Delta2 |
- |
R1* |
- |
| Delta3 |
- |
R1 |
R2* |
| Delta4 |
R1* |
- |
R2 |
| Delta5 |
R1 |
R3* |
R2 |
Table 2: BubbleUp Example
Policy BubbleUp ``bubbles up'' empty slot instances in the future so they occur in the next slot instance. Thus, if there is a free slot, it always occurs in the very next time slot, and the maximum delay a new request faces is limited. In particular, the worst delay occurs if the new request arrives just after a slot has started. It then has to wait for the next slot (Delta = gamma(CYL) + S/TR), plus the time for its own seek to be completed (gamma(CYL)) to reach the playback point. Thus, the worst case latency:
Tlatency = 2 * gamma(CYL) + S/TR (Eq. 1)
is independent of Nlimit. When two new requests arrive at the server and the system is currently servicing fewer than Nlimit - 1 requests, we can still service these two new requests immediately in consecutive slots. The latency for the second request is larger than the first one by gamma(CYL) + S/TR.
A fast-scan operation is initiated by an ongoing request that decides to jump to another segment of the video. Fast-scans can be supported either by providing thumb-nail pictures to allow the viewer to select a video sequence to jump to, or by playing a separate fast (skipping frames) version of the video that leads to the desired segment of the film [BGMJ94, ORS96]. Since a fast-scan operation is initiated by an interactive user, having fast response time is critical, as we have discussed.
If open slots are available, we can treat a fast-scan request just like a new request, scheduling for the next open slot (and removing the old request from the slot it was assigned to). However, if no slots are available, then the fast-scan cannot be serviced. This is illustrated by the following example, which also motivates an extension to BubbleUp. We continue with the previous example, starting with from the 5th time unit (Delta 5).
To service the fast-scan request right away in s.2 as well as to avoid data underflow for the delayed requests, BubbleUp must increase the segment size from S to S'. Let us assume that we only wish to service (with low latency) one fast-scan operation per service cycle. In this case, the new segment size S' must be able to sustain the playback for the possible delay of one extra service slot. While an expression for S' is derived in Section 4, for this example it suffices to say that S' should be large enough to sustain the playback time of 4 Delta. Assuming that the system now reads segments of size S', we repeat the example from the beginning of Delta 5. Table 3 shows the execution; the steps are as follows:
| Time |
s.1 |
s.2 |
s.3 |
| Delta5 |
R1 |
R3* |
R2 |
| Delta6 |
R2 |
R1 |
R3* |
| Delta7 |
R2* |
R1 |
R3 |
| Delta8 |
R2 |
R1* |
R3 |
Table 3: Fast-Scan Example
The above example shows that BubbleUp can enlarge the segment size to S' so that the service for the scheduled requests can be postponed to support fast-scan operations. The more fast-scans the media server is designed to support in a service cycle, the larger S' needs to be.
BubbleUp can elect to use its resources to service new requests or fast-scan operations. Continuing with the example from Section 3.2, we extend the execution by three more slot instances. Let a new request R4 arrive in Delta 8 and let request R2 depart the server (either the viewer stops the playback or the playback ends) in Delta 10. Table 4 shows the sample execution from slot Delta 8 to Delta 11. Time slots marked with ``NA'' do not exist.
| Time |
s.1 |
s.2 |
s.3 |
s.4 |
| Delta8 |
R2 |
R1* |
R3 |
NA |
| Delta9 |
R2 |
R1 |
R4* |
R3 |
| Delta10 |
R2 |
R1 |
R4 |
R3* |
| Delta11 |
R1* |
- |
R4 |
R3 |
Table 4: Switch Example
The example demonstrates that BubbleUp has the flexibility to shift resources from supporting fast-scans to supporting additional streams, and vice versa.
We now describe policy BubbleUp formally. Let s.i, for i = 0,1,2,...,Nlimit-1, denote the service slots. The slots are Delta = T/Nlimit apart. Let psi denote the pointer to the current service slot that is being serviced by the disk, and theta denote the pointer to the service slot in which the request initiates the fast-scan operation. Let Mlimit be the maximum number of fast-scans permitted in a service cycle T, and n be the number of fast-scans that have been serviced in the cycle (n <= Mlimit). For bookkeeping, BubbleUp maintains two sets of data: 1) s.i.R records the request scheduled to be serviced in the i'th service slot, and 2) s.i.N records the number of times the request that is currently scheduled in the i'th slot has been delayed (bumped) in the cycle due to fast-scans (s.i.N <= Mlimit). We use lambda(new) to represent the newly arrived request. Figure 2 shows policy BubbleUp.

Figure 2,3,and 4: Policy BubbleUp and Procedures
Every Delta = T/Nlimit seconds, the system services a slot. The first key in policy BubbleUp is the step where the current service slot s.psi is empty (s.psi.R = nil) and there is neither a new nor a fast-scan request (step 2(c) in Figure 2). When this happens, policy BubbleUp swaps slot s.psi with the next occupied slot, and makes the empty slot available in the future. Procedure Swap in Figure 4 describes how a swap slot is chosen and the amount of data to retrieve for the swapped request.
The second key in policy BubbleUp is the steps where the scheduled requests are delayed to service a fast-scan request. This can happen either when the system still has empty slots (step 2(b)) or when the system is fully loaded (step 3(b)), as long as the number of fast-scans issued in the cycle has not exceeded the limit (n < Mlimit). In both steps, procedure Bump is invoked to push some scheduled requests backward so that the fast-scan request can be serviced promptly.
Figure 3 describes how procedure Bump works. Procedure Bump pushes the requests in front of the service slot that initiates the fast-scan request (s.theta) one slot back. This not only opens up the current slot to service the fast-scan request, but also garbage-collects the slot in which the request issues the fast-scan. Another important function of procedure Bump is to keep track of how many times a request has been bumped in a service cycle (stored in s.i.N). This information is used in procedure Swap to determine how much data to retrieve for the swapped request (discussed shortly).
Figure 4 describes procedure Swap formally. Procedure Swap determines which slot to swap in the second step of the execution. The slot to swap is the first occupied slot due up for service. If all slots are empty, then the procedure does nothing. After a swap candidate is chosen, procedure Swap calculates how much data to retrieve for the swapped request. First, procedure Swap determines how many slots (denoted as Nslots) the swapped request has to be moved forward. Next, procedure Swap determines how many times the swapped request has been moved backward due to the fast-scans serviced in the cycle (can be found after 3(a) in s.psi.N). Since the swapped request was scheduled to run out of data in Nslots + (Mlimit - s.psi.N) slots away, moving it Nslots forward leaves S' * (Nslots + Mlimit - s.psi.N)/ (Nlimit + Mlimit) amount of data in the buffer. To replenish the buffer to S' requires the data retrieval size to be:
S' * (Nlimit - Nslots + s.psi.N) / (Nlimit + Mlimit).
The value of s.psi.N is reset at the end of Swap (Step 3(e)) since the data in the buffer for the swapped request has been filled up to S' to take up to Mlimit bumps.
Policy BubbleUp can be enhanced beyond what we have described here. In particular, instead of checking if n < Mlimit before calling procedure Bump (under steps 2(b) and 3(b) in Figure 2), BubbleUp can check if each request to be bumped satisfies s.i.N < Mlimit. Thus, as long as the affected requests have sufficient data in the buffer to be delayed, the fast-scan request can be admitted even though n can be equal to or larger than Mlimit. We do not consider this enhancement further in the rest of this paper.
We have assumed so far that a video is laid out contiguously on the disk in its entirety. However, policy BubbleUp does not require such a stringent data placement policy.
To keep the seek overhead of an IO to at most gamma(CYL), BubbleUp requires that the data read by each disk IO is physically contiguous on the disk. Since each IO may read variable amounts of a segment, we have to carefully store data on the disk. For example, suppose that we store the segments S'1, S'2, S'3 ... of a particular presentation in different places on disk. It could be the case that in the first cycle we read three fourths of S'1, and then need to read a full segment's worth of data in the second cycle. Thus, in the second cycle we need to read 1/4 of S'1 and 3/4 of S'2, requiring two IOs. This violates our one IO per request rule.
To remedy this problem, we propose placing data on the disk in contiguous chunks following two rules:
To illustrate, consider a video stored in three chunks: chunk A contains segments 1, 2, and 3; chunk B contains segments 3 and 4, and chunk C segments 4, 5, 6, and 7. It is clear that BubbleUp can now read one segment worth of data in a single IO starting at any point of the video. For instance, if it needs to read a fraction of S'2 and S'3, it can read from chunk A; if it needs to read a fraction of S'3 and S'4 it reads from chunk B.
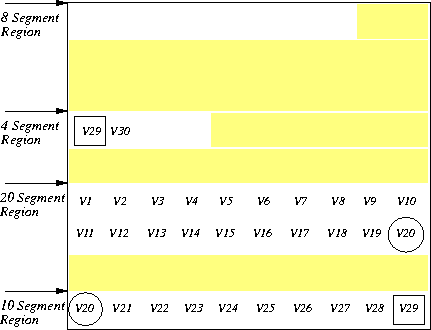
As we break up a video into more and more chunks, we have higher storage overhead. At the extreme, all chunks contain two segments, and every segment is replicated, for a 100% storage overhead. Thus, we would like to store each video on disk using as few chunks as possible. The following example illustrates a good policy for achieving such allocation. Say we have a 30 segment video to place on disk. We denote the i'th segment of the video by Vi. Figure 5 presents the disk layout, with the unshaded regions representing the available space on disk. These free regions can accommodate (from top to bottom) 8, 4, 20, and 10 segments respectively. We first use a ``largest fit'' policy, using the largest available spaces on disk to hold the largest possible chunks. For the last chunk we use instead a ``best fit'' strategy in order to reduce disk fragmentation. Figure 5 shows the result of using these policies. The first 20 segments of the video, from V1 to V20 are placed in the largest 20 segment region. Then, we have to replicate V20 at the beginning of the second chunk, and place segments V20 to V29 in the next largest 10 segment region. The last chunk holds a copy of V29 together with V30. It is placed in the smallest region that can hold it, i.e., it goes into the 4 segment region.
The ``largest fit'' policy reduces the number of chunks, decreasing the replication overhead to the minimum possible. The ``best fit'' policy for the last chunk reduces fragmentation, and is beneficial for future allocations. We believe that under normal circumstances (i.e., a disk that is not terribly fragmented), videos can be stored in small number of chunks, and the replication overhead will be minimal.
Three factors together determine the memory requirement and hence the throughput of a media server: disk seek overhead, the variability of the IO time, and the degree of memory sharing among the requests. In this section, we analyze these factors for scheme Fixed-Stretch (the underlying scheduling policy of BubbleUp). We also compare it with a representative disk scheduling policy, Sweep, which minimizes disk seek overhead. Finally, we study the impact on throughput of the extra data read when BubbleUp handles fast-scans. In Section 5 we also evaluate the Group Sweeping Scheme (GSS) [YCK93], a scheme that can be thought of as a hybrid between Fixed-Stretch and Sweep. However, due to space limitations, in this section we do not discuss the GSS analysis. (The analysis can be found in [CGM97a].)
The throughput analysis for Fixed-Stretch is independent of whether policy BubbleUp is used or not, as long as BubbleUp does not read larger segments for fast-scans. For now, assume that larger segments are not used.
Fixed-Stretch services requests in cycles each lasting T time units. As we have discussed in Section 2, the period T must be large enough so that all necessary IOs can be performed. The period T therefore must be larger than or equal to the worst case seek and transfer times, i.e., T >= Tseek + Ttransfer. For optimal performance, however, we take the smallest feasible T value, since otherwise we would be wasting memory resource. That is,
T = Tseek + Ttransfer = Nlimit * (gamma(CYL) + s/TR). (Eq. 2)
In a feasible system, the amount of data retrieved in a period must be at least as large as the amount of data displayed. That is, S >= DR * T, where DR is the display rate. (Recall that Table 1 summarizes our parameters.) We refer to this constraint as continuity constraint. However, if we want a stable system, the input rate should equal the output rate, else in every period we would accumulate more and more data in memory. Thus, we have the equation
Substituting T = S/DR (Eq. 3) into Equation 2, we can solve for S, the segment size needed to support the Nlimit requests (without fast-scan):
S = (Nlimit * gamma(CYL) * TR * DR) / (TR - (DR * Nlimit)) (Eq. 4)
From Equation 4, it is clear that the segment size is directly proportional to the seek overhead function gamma(CYL), given TR, DR, and Nlimit.
For scheme Sweep, since gamma is a concave function [KTR94, RW94b, TPBG93], the largest value of the total seek overhead occurs when the segments are equally spaced on the disk. This means that the worst case seek overhead per request is gamma(CYL/Nlimit). Thus, the equations for Sweep are identical to the above, except that gamma(CYL) is replaced by gamma(CYL/Nlimit).
For Fixed-Stretch (without considering fast-scan), the time between servicing IOs for a request is capped by T. As such, S amount of memory can sustain playback without violating the continuity constraint stated in Equation 3. The memory requirement (without sharing of buffers) for Fixed-Stretch is therefore Nlimit * S.
For Sweep, however, although in a period we read only S bytes for each stream, it turns out we need a buffer of twice that size for each stream to cope with the variability in read times. To see this, consider a particular stream in progress, where we call the next three disk arm sweeps A, B, and C. Assume that the segments needed by our stream are a, b, and c. It so happens that because of its location on the disk segment, a is read at the beginning of sweep A, while b is read at the end of sweep B, 2 * T time units after a is read. At the point when a is read we need to have in memory 2 * S data, to sustain the stream for 2 * T time.
When segment b is read, we will have only S bytes in memory, which is only enough to sustain us for T seconds. Fortunately, because b was at the end of its sweep, the next segment c can be at most T seconds away, so we are safe. Actually, c could happen to be the very first segment read in sweep C, in which case we would again fill up the buffer with roughly 2 * S data (minus whatever data was played back in the time it takes to do both reads).
Intuitively, what happens is that half of the 2 * S buffer is being used as a cushion to handle variability of reads within a sweep. Before we actually start playing a stream we must ensure that this cushion is filled up. In our example, if this stream were just starting up, we could not start playback when a was read. We would have to wait until the end of sweep A (the sweep where first segment a was read) before playback could start. Then, no matter when b and c and the rest of the segments were read within their period, we could sustain the DR playback rate.
Adding a cushion buffer for each request doubles the memory required. For Nlimit requests, the total memory for Sweep is 2 * Nlimit * S (ignoring sharing of free space among buffers). Note that although Sweep has a smaller segment size, it needs a two-segment buffer for each request to cope with the IO time variability.
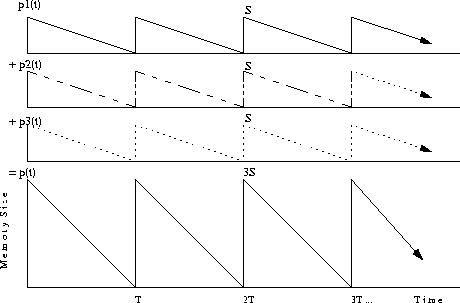
Figure 6(a): Memory Requirement Examples
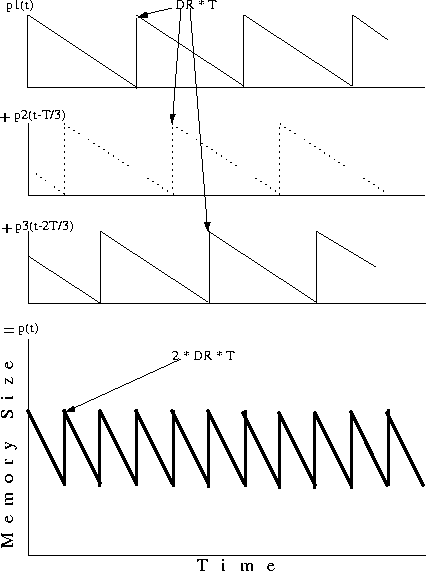
Figure 6(b): Memory Requirement Examples
Memory can be shared among Nlimit requests. Figure 6 depicts three streams using the memory resource. When an IO occurs, the memory buffer of each stream is filled with S amount of data. It is then drained by the display device at rate DR in the next period T. This pattern repeats itself until the playback ends. The bottom curves show the total memory used, i.e., the sum of the top three curves.
Note that when the IOs are close to each other as shown in Figure 6(a), the peak memory requirement (bottom curve) is 3 * S. On the other hand, Figure 6(b) shows that when the IOs are spaced out with equal distance, the memory requirement is reduced to 2 * S. In general, a scheme like Sweep that minimizes seek latency has shorter gaps between IOs, and hence the memory sharing is limited. On the other hand, when IOs are delayed with equal gaps, like in the case of Fixed-Stretch, the memory sharing factor is optimal [CC96, CGM97a, NY94]. Thus, Fixed-Stretch has an important advantage over Sweep with respect to memory sharing.
In [CC96, CGM97a] we derive precise formulas for the memory required by each scheme, assuming sharing of free space among requests. Due to space limitations, here we simply report the expressions: The memory requirement for Fixed-Stretch is
MemMin(Fixed-Stretch) = S * (Nlimit+1)/2 + (Nlimit * gamma(CYL) * DR). (Eq. 5)
The memory requirement for Sweep with memory sharing is
MemMin(Sweep) = (Nlimit - 1) * S + Nlimit * DR * (T - (Nlimit - 2) * S/TR). (Eq. 6)
From this memory requirement one can compute the maximum throughput given some fixed amount of available memory. For example, one can assume that Nlimit = 1 and see if the computed MemMin(Sweep) is less than the available memory. If so, we can try Nlimit = 2 and so on, until we find the largest feasible value of Nlimit. This last value would be the maximum throughput supportable.
Assuming that up to Mlimit fast-scan operations are allowed in each service cycle, BubbleUp (and Fixed-Stretch) now has to read more data to sustain the playback for the duration of Nlimit + Mlimit service slots, rather than Nlimit.
We now derive the memory requirement for supporting Mlimit fast-scan requests in a cycle T. If the server allows Mlimit fast-scan operations per service cycle, then the segment size, instead of being S, must be S' = ((Nlimit + Mlimit)/Nlimit) * S. When a request arrives, ((Nlimit + Mlimit)/Nlimit) * S is read into its buffer. If no fast-scan operations are issued in the service cycle, only S amount of data is consumed, and hence only S amount is replenished in the subsequent cycle. If Mlimit fast-scans occur in the service cycle, then another ((Nlimit + Mlimit)/Nlimit) * S amount of data needs to be replenished in the next service cycle. In the worst case, all IOs in a cycle transfer ((Nlimit + Mlimit)/Nlimit) * S amount of data. Rewriting the continuity requirement in Equation 3, we get
S/DR = Nlimit * (gamma(CYL) + ((Nlimit + Mlimit) * S)/(Nlimit * TR). (Eq. 7)
Solving for S we get
S = (Nlimit * gamma(CYL) * TR * DR)/(TR - (DR*(Nlimit + Mlimit))). (Eq. 8)
The segment size S' for supporting Mlimit fast-scan operations in a service cycle is
S' = (Nlimit + Mlimit) * S/Nlimit. (Eq. 9)
This S' is to replace the S in Equation 5 to compute the total memory requirement to support Nlimit streams and Mlimit fast-scan operations.
In this section, we use a case study to compare the initial latency and throughput of BubbleUp (with Fixed-Stretch), Sweep and GSS. For our evaluation we use the Seagate Barracuda 4LP disk [SGT96]; its parameters are listed in Table 5.
| Parameter Name | Value |
| Disk Capacity | 2.25 GBytes |
| Number of Cylinders, CYL | 5,288 |
| Min. Data Transfer Rate, TR | 75 Mbps |
| Max. Rotational Latency Time | 8.33 ms |
| M.n. Seek Time | 0.9 ms |
| Max. Seek Time | 17.0 ms |
| alpha1 | 0.6 ms |
| beta1 | 0.3 ms |
| alpha2 | 5.75 ms |
| beta2 | 0.0021 ms |
Table 5: Seagate Barracuda 4LP Disk Parameters
For computing the seek overhead we use the following function [KTR94, RW94b]:
gamma(d) = alpha1+(beta1*sqrt(d)) + 8.33 if d < 400
gamma(d) = alpha2 + (beta2 * d) + 8.33 if d >= 400
In each seek overhead we have included a full disk rotational delay of 8.33 ms. The rotational delay depends on a number of factors, but we believe that one rotation is a representative value. One could argue that rotational delay could be eliminated entirely if a segment were an exact multiple of the track size. (In that case we could start reading at any position of the disk.) However, the optimal segment size depends on the scenario under consideration, so it is unlikely it will divide exactly into tracks. If we assume that the first track containing part of a segment is not full, then in the worst case we need a full rotation to read that first portion, even with an on-disk cache. If we assume that the last track could also be partially empty, then we would need a second rotational delay, and our 8.33ms value might be conservative! Note incidentally that we use a full rather than an average rotational delay since we are estimating a worst case scenario.
For Sweep, the worst initial latency happens when a request arrives just after the disk head has passed over the first segment of the media. The request must wait for a cycle (T) until its first segment can be retrieved. As discussed in Section 4.2, playback cannot start right away, since this first segment just fills up the playback cushion. Actual playback can start at the end of the first cycle, which in the worst case can be another T seconds away. The worst initial latency is therefore Tlatency = 2T. The latency expression for GSS is the same, although the actual values can be higher because GSS typically uses a larger segment size to improve throughput. As shown in Section 3, the latency expression for BubbleUp (with Fixed-Stretch) is Tlatency = 2 * gamma(CYL) + S/TR.
Note that in a particular service cycle T, schemes Sweep and GSS may have some slack time, and it may be possible for the disk arm to temporarily alter its sweep pattern to service a new request [TL94]. Thus, if there happens to be slack available, a particular new request could be started earlier (although we still have to fill the cushion buffer before playback starts). However, the amount of slack left in the cycle is stochastic, and hence cannot be relied on in computing the worst case initial latency.
We show in Figure 7 that BubbleUp improves the initial latency significantly compared to Sweep. While the initial latency of Sweep goes up superlinearly with Nlimit, BubbleUp maintains an almost constant initial latency which is under a quarter of a second.
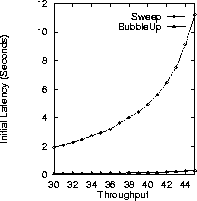
Figure 7: Initial Latency vs. Throughput
Next we compare the throughput of BubbleUp with Sweep and GSS. We plot the throughput figure by first computing the memory requirement using Equation 5 for BubbleUp and Equation 6 for Sweep (for GSS please refer to [CGM97a]), then picking the largest Nlimit each scheme can achieve under a given memory configuration. Figure 8 shows BubbleUp consistently supports up to one more stream than Sweep does when memory is limited. Both schemes support the same number of streams when memory is abundant. Compared to the optimal throughput GSS can achieve, BubbleUp trails by at most one stream.
These results show that minimizing disk latency alone (like Sweep does) does not necessarily lead to better throughput. A scheme that conserves memory like BubbleUp (with Fixed-Stretch) by fixing the scheduling order and improving memory sharing achieves comparable, sometimes better, throughput. Furthermore, as we have shown, BubbleUp minimizes initial latency (with essentially no throughput penalty), and this gives it a big edge over the other schemes. Thus, for interactive applications that require fast response time, BubbleUp may be the choice.
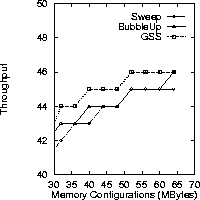
Figure 8: Throughput vs. Memory
Figure 9 shows the memory requirement for supporting 1, 2, and 6 fast-scan operations on top of the Nlimit requests. The horizontal axis represents Nlimit, while the vertical axis shows the total memory needed to support that number of requests plus the Mlimit fast-scans. The marginal memory requirement goes up as throughput (Nlimit) or the number of fast-scan operations (Mlimit) increases. For instance, supporting one fast-scan (Mlimit = 1 instead of zero) at Nlimit = 40 requires 2.7 MBytes of additional memory. By comparison, the incremental memory requirement at Nlimit = 35 for one fast-scan (compared to none) is 1.0 MBytes. Supporting a second fast-scan operation at Nlimit = 40 needs 3.4 MBytes of additional memory. This is not a surprise since Equation 8 shows that as Nlimit + Mlimit grows the denominator of Equation 8 approaches zero, causing S to grow super-linearly.
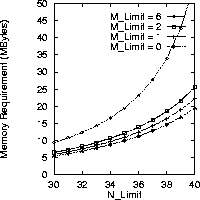
Figure 9: Memory Required for Fast-Scans
Note that it is cheaper to support fast-scans (i.e., to increase Mlimit) than to support the same number of additional streams (i.e., to increase Nlimit). For instance, Figure 9 shows that supporting Nlimit = 35 plus Mlimit = 6 requires 19.5 MBytes of memory (the first line from the top); however, supporting Nlimit = 40 (the bottom line at Nlimit = 40) also needs the same amount of memory. In this case, a reduction in throughput of five requests supports at least six fast-scan operations (Mlimit becomes the lower bound if we make the enhancement discussed in the end of Section 3.4). This illustrates that supporting fast-scan operations incurs only a sub-linear tradeoff with throughput. Which of the two operations to favor in a media server, new requests (which increases throughput) or fast-scan, is a policy decision.
In closing this section we make one important point. The results of this section are for a specific hardware scenario. However, we believe that our general conclusions hold even under different disk parameters. Reference [CGM96] presents results that support this claim, but due to space limitations they cannot be given here.
In this paper we proposed a disk and memory management scheme, BubbleUp, that minimizes initial latency for servicing new and fast-scan requests. To minimize initial latency, BubbleUp, always makes the available disk bandwidth and memory resource ready for servicing a new request. In addition, BubbleUp can prefetch additional data for each request so that when a fast-scan request arrives, it can delay service to the scheduled requests in order to service the fast-scan promptly. We showed that BubbleUp typically keeps the initial latency under a quarter of a second even when the media server is heavily loaded. We believe that this low latency is critical in interactive multimedia applications.
To implement BubbleUp, the disk arm must be given freedom to move to any location on the disk so that the scheduling order of the requests can be changed. This freedom is made possible by our underlying Fixed-Stretch policy. Intuitively, increasing disk latency between IOs may lead to throughput degradation. However, we showed that spacing out IOs conserves memory, and BubbleUp (without fast-scan support) is able to achieve throughput near the optimal of the GSS scheme, and outperform a conventional elevator disk arm scheduling policy like Sweep. In short, BubbleUp minimizes initial latency without adversely affecting throughput.
It is important to note that BubbleUp can be used with any commercial, off-the-shelf disks since it does not require any modification to the device drivers. The entire implementation of BubbleUp can be above the device driver layer, since BubbleUp only needs to queue an IO request after the completion of the previous one. Another benefit of BubbleUp is that even when the system is fully loaded, the disk arm usually has slack between IOs. This slack could be used to service short duration conventional file IOs, such as for accessing closed captions for the playing videos. (To efficiently use the slack, however, may require implementing BubbleUp at the device driver level.) Thus, BubbleUp may be a good resource manager for multimedia file systems. We also believe that BubbleUp can be used in a multi-disk environment, and we are currently studying its implementation and performance in such a case.