![[IMG]](model-1.gif)
Figure 1. Global integration of a distributed
visual information system.
Crowne Plaza Hotel, Seattle, USA
With the advances in multimedia databases and the popularization of the Internet, it is now possible to access large image and video repositories distributed throughout the world. One of the challenging problems in such an access is how the information in the respective databases can be summarized to enable an intelligent selection of relevant database sites based on visual queries. This paper presents an approach to this problem that is based on image content-based indexing of a metadatabase at a query distribution server. The metadatabase records a summary of the visual content of the images per database through image templates and statistical features characterizing the similarity value distributions of images. The selection of databases is done by searching the metadatabase using a histogram-based ranking algorithm that use query similarity to a template and the features of databases associated with the icon. The database selection mechanism have been implemented as a metaserver and extensive experiments have been done to demonstrate the effectiveness of the database ranking algorithm.
Database selection, content-based retrieval, distributed visual information systems, metadata.
With the popularization of the Internet, it has now become possible to access large image and video repositories (visual databases) distributed throughout the world. Such access is becoming increasingly important in a number of applications, such as medical diagnostics, manufacturing, education, surveillance, and distributed publishing. In such applications, information from visual databases distributed at remote locations must be made available at other locations for purposes ranging from diagnostics, distance learning, to electronic commerce. Accessing these repositories in a distributed setting over either a proprietary or a public network poses a number of challenges.
In a typical use scenario, a query generated by a client needs to be distributed to relevant visual databases. This is usually done through a metaserver that selects the target multimedia database site(s) and poses the query to the respective databases in an acceptable form. The searching mechanism of the database searches its repository for possible answers to the posed query. The answer is then fed back to the metaserver for eventual relaying to the client. This general framework of database selection is illustrated in Figure 1 through a metaserver which includes a metadatabase and metasearch agent.
Figure 1. Global integration of a distributed
visual information system.
Intelligent site selection has been attempted based on text information [16, 20 ]. Most work can be categorized based on the Information Retrieval (IR) model it uses. For example, GLOSS from Standford [9, 8] uses Boolean and vector-space retrieval models of document retrieval to estimate the number of potentially relevant documents in a database for a given query. Vector-space retrieval model is also used in [25] to produce a list of potentially relevant World-Wide Web sites. Probabilistic retrieval models are used in [3, 19, 7]. In the case of [3], document collections are summarized using collection frequency information for each keyword term together with the inverse collection frequency of different terms. An inference network then uses this information to rank the collections for a given query. In [7], a decision-theoretic approach was proposed which uses expected recall-precision curve, expected number of relevant documents and cost factors for query processing and document delivery to make selection decision. Some systems use artificial intelligence techniques to locate relevant resources. Examples of such systems include [4, 15]. Finally, many systems [13, 17, 12, 6] use a simple ``directory of services'' for preliminary site selection. The ``directory of services'' maintains descriptions of all participating databases. The contents of databases are generally modeled as a set of attributes. Queries, usually consisting of Boolean combinations of the desired attribute-value pairs, are first submitted to the ``directory of services'', which then provides users with hints on databases to search.
Although commercial systems are being developed that allow multiple text databases to be accessed over the Internet via SQL, ODBC or Perl gateways [23], new technical issues arise due to the nature of the visual data, including images and video data. With the advent of content-based querying of visual databases [14, 11, 1, 22], it is apparent that traditional methods of designing such databases using proprietary methods of query specification and search based on traditional indexing approaches may not be suitable in these settings where the remote user's queries may be unanticipated and referring to image content that is as yet unextracted. In addition, the time-consuming nature of content-based queries requires an intelligent selection of target databases to ensure acceptable response time.
We observed that the selection of databases can be done by content-based indexing of a metadatabase. The metadatabase records a summary of the visual content of the images per database in a suitably abstracted form. Searching the metadatabase involves determining the visual similarity of the query with the abstracted visual information recorded about the databases in the metadatabase. A similarity measure captures the visual similarities of images in databases to image templates. Image database organization based on templates has been studied in [24, 26]. Next, a distribution of the similarity values of images of a database to a template is derived. From the distribution, statistical features are computed that capture the likelihood of a database containing images that are relevant to a template. The features describing the links between databases and templates are pre-computed and stored in the metadatabase. On posing a query, its visual similarity to templates is computed. The query similarity values are then used against the information in the metadatabase to derive a ranking of databases with respect to the posed query.
We recently outlined an approach, termed mean-based approach, to the problem of database selection that is geared towards handling visual content-based queries [5]. The statistical features used to determine the likelihood of a database containing a given visual query include number of samples, mean and variance of similarity distribution, etc.
In this paper, we propose a new ranking approach, termed histogram-based approach, which is based on not only the statistics of the similarity distribution (represented as a histogram) but also the locations of the database images within the image cluster. Comparing with the previous proposed mean-based approach, the histogram-based approach provides more accurate selection of relevant databases for given visual queries.
The rest of the paper is organized as follows. In Section 2, we present the rationale of database selection through image template indexing of a metadatabase. In Section 3 we present the histogram-based algorithm for ranking databases based on template similarity to visual queries. Details of experiments that compare the histogram-based and mean-based ranking algorithms are reported in Section 4. Concluding remarks are offered in Section 5.
To support efficient visual queries, relevant databases must be selected for visual queries without detailed examination of all images of database for possible matches. Clearly, it is not desirable to move the complete machinery of image content-based search used in the database engine to the metaserver to determine database relevance. Also, it is not possible to create off-line, an indexed set of database sites containing relevant images to queries, as that requires an anticipation of all possible visual queries. To address these problems, we propose an intermediate approach wherein the information in the images of the database is summarized and represented in a suitably abstracted form in a metadatabase. The relevant databases for a particular query are determined by an image content-based indexing of the metadatabase. This involves determining the visual similarity of the query with the abstracted visual information recorded about the databases.
We assume various feature classes in visual databases can be
represented by a set of image templates collected from local databases.
An image database can
belong to one or more templates. Under each template, statistical information
for each database is stored in the metadatabase.
A query q may consist of subqueries
![]() ,
(
,
(![]() ),
with each subquery representing
a feature class (i.e., texture pattern, color
pattern, shape pattern, text, etc.) to
be retrieved in the database images.
Each subquery may then match with one or more
templates
),
with each subquery representing
a feature class (i.e., texture pattern, color
pattern, shape pattern, text, etc.) to
be retrieved in the database images.
Each subquery may then match with one or more
templates ![]() ,
(
,
(![]() ).
The subquery similarity to templates and related statistical information
of databases
).
The subquery similarity to templates and related statistical information
of databases ![]() (
(![]() )
are then used to derive a ranking of the databases
with respect to the subquery. The rankings
of the databases for the subqueries are then merged to yield a
final set of the databases for the given query.
Figure 2 shows the relationships between a query,
templates, and databases.
)
are then used to derive a ranking of the databases
with respect to the subquery. The rankings
of the databases for the subqueries are then merged to yield a
final set of the databases for the given query.
Figure 2 shows the relationships between a query,
templates, and databases.
![[IMG]](query-1.gif)
Figure 2. Query, templates, and databases.
We will now formulate the database selection strategy for visual queries. We focus on using image templates as the abstraction of databases. Image templates are prototypical regions that are representative of the feature in an underlying scene. For example, a geographical image database may be summarized through a set of templates representing textures corresponding to residential areas, grass, water, and agricultural areas. Our previous work on iconic representations had demonstrated their usefulness in clustering of images within a database, as well as querying to texture content within images [26, 21]. Our similarity measure is based on the distance between feature vectors of images in the feature space, with 1.0 representing the highest similarity and 0.0 representing no similarity. The measurement is determined by computing statistics of texture features such as contrast and directionality. The effectiveness of this measure in capturing directionality. The effectiveness of this measure in capturing visual similarity to templates had been demonstrated by showing the existence of different similarity ranges for distinct clusters. For example, given an image template shown in Figure 3, images in cluster (4), with similarity measures in the range of [0.07,0.15], are the least similar ones to the image template. Images in cluster (1), with similarity measures in the range of [0.71,0.85], are the most similar ones to the image template. Clearly, images belonging to cluster (1) are considered to have similar texture features to that of the image template used in the figure. Since we use distance-based similarity measure, images with the same distances to an image template will have the same degree of similarity with respect to that template.
![[IMG]](dbimgs.gif)
Figure 3. Template and database images from Brodatz Album.
Our use of image templates for visual abstraction is based on the above observation. That is, if a query and an image are both visually similar, then it is likely that they have close degree of similarity to the same template. Figure 4 shows the situation in the two dimensional feature space. Given a template T, which is generally located near the center of an image cluster, images with similar features to T are usually located near T, with small distances to T. Images without similar features to T are normally located far away from T, with large distances to T. In addition, for image q, with a distance to template T, images similar to q will normally have small distances to q (i.e., located within the shaded area Q) and thus have similar distances to template T. This property can be observed in Figure 3. For example, all three images in cluster (1) have small distances to each other and they all have similar distances to the given template.
Note that one cannot say that if two images both have the same degree of similarity (or distances) to a template, then they are definitely similar to each other. As it is shown in Figure 4, both images q and m have similar distances to template T, but the distance between q and m is large. It is thus possible that q and m are not similar.
![[IMG]](trans.gif)
Figure 4. The relationship between images and template.
We will now describe how to determine the most relevant region
for any image query q.
We first uniformly divide each image cluster represented by a
template T into small partitions.
The division is centered at template T, and is based on the
image features. Given a feature space consisting of n features,
we can select the k most important features. The feature space
can then be represented as a k-dimensional rectangular coordinate system
with each important feature as a dimension.
Let ![]() be the
axes of the coordinate system,
we define
be the
axes of the coordinate system,
we define ![]() as the
cut that is parallel to the axis
as the
cut that is parallel to the axis
![]() ,
,
![]() , and
passes through template T.
We then divide each image cluster along each
, and
passes through template T.
We then divide each image cluster along each ![]() ,
,![]() ,
to yield
,
to yield ![]() partitions.
A cut along any
partitions.
A cut along any ![]() will divide an image cluster into two
portions, denoted
will divide an image cluster into two
portions, denoted ![]() and
and ![]() portions, respectively.
Each partition
portions, respectively.
Each partition ![]() can then be represented by a
vector
can then be represented by a
vector ![]() ,
where
,
where ![]() .
For example, a partition with a vector representation in the domain of
.
For example, a partition with a vector representation in the domain of
![]() indicates the intersection of the
indicates the intersection of the ![]() portion of the
portion of the
![]() and
and
![]() portion
of the
portion
of the ![]() .
Let
.
Let ![]() be the
coordinate for template T, and
be the
coordinate for template T, and
![]() be the
coordinate of an image q, we compute
a vector
be the
coordinate of an image q, we compute
a vector ![]() , where
, where
![]()
The image q is grouped into partition
![]() of template
T, if
of template
T, if
![]() .
Figure 5 illustrates the partitioning in a
two-dimensional feature space. Image q with coordinates
.
Figure 5 illustrates the partitioning in a
two-dimensional feature space. Image q with coordinates
![]() is
grouped into
is
grouped into ![]() ,
because the corresponding vector U is
,
because the corresponding vector U is
![]() and vector of partition
and vector of partition ![]() is also
is also
![]() .
Note that although we only use k important features for
the partitioning, in retrieving images, we will
use the original feature vector with all the n features.
.
Note that although we only use k important features for
the partitioning, in retrieving images, we will
use the original feature vector with all the n features.
![[IMG]](subcluster.gif)
Figure 5.Image cluster divided with two important features.
Let query image q has similarity sim to template T.
The relevance region of q with respect
to T is defined as the part of a
partition that has similarity
![]() to T,
where
to T,
where ![]() is an offset
value.
is an offset
value. ![]() should be
determined by experiments.
Figure 6 shows the definition of the
relevance region
should be
determined by experiments.
Figure 6 shows the definition of the
relevance region ![]() for image q which is located in
partition
for image q which is located in
partition ![]() in
the two-dimensional feature space.
in
the two-dimensional feature space.
![[IMG]](histfea.gif)
Figure 6. A relevance region that is within partition.
Our database selection approach is developed based on the relevance region. For a query image q, the relevance region provides a good estimation of the area where exactly matched or highly relevant images to image q will fall within. Database sites with more images in the relevance region are considered more likely to contain relevant images to image q, therefore are ranked higher.
We design a metadatabase and a metasearch agent to support the database selection. Given a set of databases at various sites, an initial metadatabase is constructed using image templates as mediums of visual abstractions. At the time that a database registers with the metaserver, the metadata about the database is supplied. These metadata include the type of media data housed, expected query form, and specialized algorithms supported. In addition, the distributions of the similarity and relative positions of database images with respect to image templates are collected. Each database image is grouped into a partition associated with an image template. For each partition, a histogram which represents the similarity distribution of the images within the partition is derived and stored in the metadatabase. The similarities and locations of database images to templates are precomputed using image feature extraction algorithms.
The metadatabase is organized into a hierarchical structure. At the lowest level, database sites are grouped under each template, the groupings are based on the similarity of database images to the template. We define an image is similar to a template if the similarity measurement between the two images is greater than a threshold. A database site can be grouped under one or more templates. At the higher level, templates are grouped according to feature classes, including keywords, texture pattern, color pattern, and shape pattern, with top-level nodes representing the most general categories of text, texture, color and shape. The hierarchical organization of the templates is similar to the image clustering organization presented within an individual multimedia database [26]. The templates presenting at the metadatabase are generally a super set of the templates presenting within an individual multimedia database. Figure 7 presents a conceptual view of the metadatabase.
![[IMG]](metadatabase.gif)
Figure 7.A conceptual view of the metadatabase.
The role of the metaserver is to accept user queries and transforms the information in the query for suitable searching of the metadatabase. It also distributes the queries to the selected database sites and relays their responses back to the user.
The templates, distributions of similarity and relative position values can be either computed as a background process by the metaserver or can be collected directly from a database when it registering with the server. Thus, although the metadata collecting process could be time-consuming, it can always be done off-line. Therefore, the metadata collecting process will not affect the efficiency of query retrieval. On the other hand, such an organization of the metadata will support efficient on-line retrieval of image queries.
In this section, we present a histogram-based algorithm for ranking databases based on computing visual similarity of queries and images of databases to templates. The discussion will follow the general database selection principle outlined in Section 2 and defines the detailed ranking algorithm based on the collected histogram metadata.
The following terminology is needed for the ensuing discussion.
Given a query image q, which may be represented as a set of subqueries
![]() , the visual similarity
of subquery
, the visual similarity
of subquery ![]() to the templates
to the templates
![]() of the
metadatabase is computed. A
set of matching templates are selected based on the following criterion:
of the
metadatabase is computed. A
set of matching templates are selected based on the following criterion:
![]()
![]()
where ![]() is defaulted to 0.05.
is defaulted to 0.05.
Let the feature space be represented as a k-dimensional rectangular
coordinate system, the coordinates of each subquery and templates
are also computed.
For each matched template with a coordinate
of ![]() ,
given a set of partitions
,
given a set of partitions
![]() ,
we compute the corresponding partition
,
we compute the corresponding partition ![]() for the subquery
for the subquery ![]() , with
a coordinate of
, with
a coordinate of ![]() using Formula (1). In addition
to the partition that the subquery falling within, the
adjacent partition may also be selected if the subquery is located
near the boundary of the two partitions.
using Formula (1). In addition
to the partition that the subquery falling within, the
adjacent partition may also be selected if the subquery is located
near the boundary of the two partitions.
where X' is the cut dividing partitions
![]() and
and ![]() , and
, and
![]() is
the distance between subquery
is
the distance between subquery ![]() and X'.
The
and X'.
The ![]() threshold varies for each dimension, and is
defaulted to 3% of the maximum distance of the feature that
represents the dimension.
threshold varies for each dimension, and is
defaulted to 3% of the maximum distance of the feature that
represents the dimension.
If the initial selection does not sufficiently prune the databases, the metaserver can perform another selection based on user feedback before submitting the query to relevant databases. Also, if no template can be found for the subquery, the metaserver has the option of creating new templates. For each new template created, all databases will be polled to obtain statistical information pertaining to the new template.
The histogram-based ranking approach computes the ranks of relevant databases according to the number of images falling within the ``relevance region'' of a given query.
We define a relevance interval [a,b] of the query q as:
where ![]() is a predefined
offset value.
is a predefined
offset value.
Let ![]() represents
the similarity histogram of images in a database db
to template t in partition c, where
represents
the similarity histogram of images in a database db
to template t in partition c, where
![]() is the
number of images within partition c that have
a similarity x.
For a given query image q, which contains a single subquery and
matches with a single template t and a set of
partitions
is the
number of images within partition c that have
a similarity x.
For a given query image q, which contains a single subquery and
matches with a single template t and a set of
partitions ![]() ,
the databases are selected by the following criterion:
,
the databases are selected by the following criterion:
where ![]() , with
, with
![]() ,
,
![]()
![]() The selected databases are
then ranked based on the value of
num(db,t,C,a,b).
This scenario is illustrated in Figure 6,
with Q representing the set of relevant images to the query,
and
The selected databases are
then ranked based on the value of
num(db,t,C,a,b).
This scenario is illustrated in Figure 6,
with Q representing the set of relevant images to the query,
and ![]() representing the set of images that are used for the ranking.
representing the set of images that are used for the ranking.
If a query contains a single subquery matching with multiple independent
templates ![]() ,
with a set of partitions
,
with a set of partitions
![]() corresponding to each template
corresponding to each template
![]() ,
Formula 5 is revised as follows:
,
Formula 5 is revised as follows:
where ![]() ,
with
,
with ![]() ,
,
![]()
![]() The selected databases are then
ranked based on the value of
The selected databases are then
ranked based on the value of
![]() .
When a subquery is matched with multiple independent templates,
the subquery will have similar feature distances to all matched templates.
Figure 8 illustrates the above scenario
in the two dimensional feature space, where the query q has similar
feature distances to both templates
.
When a subquery is matched with multiple independent templates,
the subquery will have similar feature distances to all matched templates.
Figure 8 illustrates the above scenario
in the two dimensional feature space, where the query q has similar
feature distances to both templates
![]() and
and
![]() .
Here, the shaded area (N) represents the images that are
used for the ranking, which
is the sum of the two relevance regions located
within
.
Here, the shaded area (N) represents the images that are
used for the ranking, which
is the sum of the two relevance regions located
within ![]() of
of
![]() and
and
![]() of
of ![]() .
.
![[IMG]](2dhistfea.gif)
Figure 8. Histogram-based approach for queries
matched with multiple templates.
If q contains a set of subqueries
![]() and
each
and
each ![]() matches with multiple independent templates
matches with multiple independent templates
![]() ,
and corresponding partitions
sets
,
and corresponding partitions
sets ![]() Formula 5 is then revised as follows:
Formula 5 is then revised as follows:
![]()
![]()
![]()
In such a case, the selected databases are not ranked.
In this section, we will explain our experiments to demonstrate the effectiveness of the histogram-based ranking algorithm. The experimental results are also compared to the mean-based ranking approach proposed in [5].
We have implemented a metaserver in a distributed visual information retrieval environment. The design approach to access the environment involves a Java-enabled browser accepting a query issued by a user. The user interface is a Java applet and the user query is in the form of an image. This image query is forwarded to the metaserver. The selected database sites are displayed to the user. The user may choose the sites to search. The names of retrieved images are then displayed to the user after the query is sent to the chosen databases. The images desired by the user can be directly retrieved from the specific databases.
A set of images based on the Brodatz collection [2] have been constructed as the testbed. We randomly constructed 11 databases. Figure 9 shows the database sizes.
We use a hierarchical approach to select the image templates. Initially, we assume there are n image templates corresponding to the n samples. We group together the two closest image templates, resulting in n-1 image templates. The process of grouping the two closest ones is repeated until having only one template. This hierarchically nested set of image templates can be represented by a tree-diagram, or a dendrogram [10]. We can cut the dendrogram at a level which yields enough number of image templates. Image templates with few children are discarded. Figure 10 shows the templates used in our experiments. The similarities between images and templates are calculated using the wavelet-based similarity comparison technique developed in [18, 21].
![[IMG]](db11.gif)
Figure 9. Database sizes.
![]()
Figure 10. Image templates used in experiments.
Two metrics are used to quantify the effectiveness of the approaches:
![]()
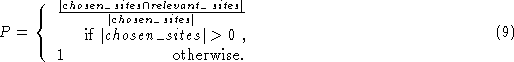
Note that the traditional recall measure is not used, since in our context, the recall measure is equivalent to the precision measure.
We randomly performed 73 queries, all of them contain a single subquery with uniform texture features. Experimental analysis on queries containing multiple subqueries can be similarly conducted.
The ![]() threshold used to select multiple templates
is set at 0.05. The similarity values between all queries and
templates ranged from 0.65 to 0.95. The number of queries
with respect to the number of matched templates and different
ranges of similarity are summarized in
Table 1. For example, there are 15 queries
that match with a single template with similarities ranging from 0.75 to 0.84.
For a query matched with multiple templates, its
corresponding similarity range is determined by the average of all
similarities between the query and matched templates.
threshold used to select multiple templates
is set at 0.05. The similarity values between all queries and
templates ranged from 0.65 to 0.95. The number of queries
with respect to the number of matched templates and different
ranges of similarity are summarized in
Table 1. For example, there are 15 queries
that match with a single template with similarities ranging from 0.75 to 0.84.
For a query matched with multiple templates, its
corresponding similarity range is determined by the average of all
similarities between the query and matched templates.
![[IMG]](ntsim.gif)
Table 1. Distribution of number of queries
based on the number of matched templates and similarity ranges.
The ![]() offset used to determine the ``relevance interval'' is
defaulted to 0.06. Later, experiments will be performed
to evaluate the effect of different interval offset values on the
performance of the ranking algorithm.
We calculated the average P and S values of all
queries by comparing
the top 4 ideally ranked databases with the top 4 databases ranked by
the ranking algorithms. The ideal rank of each database site was
determined by measuring the similarity between each given
query to all database images.
Databases with at least 5 images that have a high similarity (i.e.,
offset used to determine the ``relevance interval'' is
defaulted to 0.06. Later, experiments will be performed
to evaluate the effect of different interval offset values on the
performance of the ranking algorithm.
We calculated the average P and S values of all
queries by comparing
the top 4 ideally ranked databases with the top 4 databases ranked by
the ranking algorithms. The ideal rank of each database site was
determined by measuring the similarity between each given
query to all database images.
Databases with at least 5 images that have a high similarity (i.e.,
![]() )
with respect to the given query are considered to
be relevant to the query. All relevant databases are then further
ranked based on the number of highly similar images. The top 4 ranked
databases were used for the experiments as the top 4 ideal ranked databases.
For the selection precision, the performance for each experiment is measured
at 3 levels: 0.75, 0.50, and 0.25 (representing high precision,
medium precision, and low precision, respectively).
For the ranking order error,
the performance for each experiment is also measured at 3 levels: 5.0
(i.e., the maximum possible mean-squared error with a selection precision
of 1.0), 10.0, and 15.0 (representing low ranking order error,
medium ranking order error,
and high ranking order error, respectively).
)
with respect to the given query are considered to
be relevant to the query. All relevant databases are then further
ranked based on the number of highly similar images. The top 4 ranked
databases were used for the experiments as the top 4 ideal ranked databases.
For the selection precision, the performance for each experiment is measured
at 3 levels: 0.75, 0.50, and 0.25 (representing high precision,
medium precision, and low precision, respectively).
For the ranking order error,
the performance for each experiment is also measured at 3 levels: 5.0
(i.e., the maximum possible mean-squared error with a selection precision
of 1.0), 10.0, and 15.0 (representing low ranking order error,
medium ranking order error,
and high ranking order error, respectively).
For the histogram-based approach, we selected the
two most important texture features as the features
for partitioning. Each image cluster is divided into 4 partitions.
Each database image is grouped into a partition using
Formula (1).
For each database and template
pair, four histograms were generated with each representing the similarity
distribution of the images within a partition.
For each query, the ![]() threshold used to select multiple
partitions is set at 20.0 for the first feature
and 6.0 for the second feature.
The experiment results for the histogram-based approach
are reported in Table 2, which show
the average P and S values
as a function of the number of matched templates and similarity ranges.
Results for the mean-based approach are reported in
Table 3.
The th threshold, introduced in [5] to
determine the
number of similar images in the mean-based approach is set at 0.60.
threshold used to select multiple
partitions is set at 20.0 for the first feature
and 6.0 for the second feature.
The experiment results for the histogram-based approach
are reported in Table 2, which show
the average P and S values
as a function of the number of matched templates and similarity ranges.
Results for the mean-based approach are reported in
Table 3.
The th threshold, introduced in [5] to
determine the
number of similar images in the mean-based approach is set at 0.60.
![[IMG]](hist.gif)
Table 2. Histogram-based approach results as
the function of number of matched templates and similarity ranges:
(a) Precision, (b) Ranking Order Error.
![[IMG]](mean.gif)
Table 3. Mean-based approach results as the
function of number of matched templates and similarity ranges:
(a) Precision, (b) Ranking Order Error.
The histogram-based approach offers better performance in both selection precision (0.79 vs. 0.72) and ranking order error (4.88 vs. 6.37). The relatively high P value (0.72) of the mean-based approach also demonstrates that the mean estimation method on ranking the databases is quite effective.
For queries based on a single template,
both histogram-based and mean-based approaches yield
high selection precision (0.87 and 0.77, respectively).
We notice a decrease of the precision for both histogram-based
and mean-based
approaches (0.71 and 0.67, respectively) while the queries
match from single template to multiple templates.
This can be explained by comparing Figures 6
and 7,
as more irrelevant images are generally
included in the ranking when the query is
matched with multiple templates, thus increase the degree of error.
The lowest ranking order error results are also from queries matched with a
single template (2.87 and 5.03, respectively).
We also noticed a deterioration of the precision of both
approaches when the degree of the similarity between query
and template is low. When the
degree of similarity is high (i.e.,
![]() ),
both approaches offer high selection precision and low
ranking order error. The results are mixed when the similarity ranges
from 0.75 to 0.84. The mean-based approach reaches its
best performance in precision (0.73), whereas the
histogram-based approach yields its
highest ranking order error (5.55). When the similarity is below 0.75,
the performance of mean-based approach is poor. However, the
histogram-based approach continues to offer
good performance. We believe the good performance of
the histogram-based approach within this similarity range
is due to the partitioning, which eliminates more irrelevant images.
We also observed that when the similarity between the query
and the template becomes low (generally below 0.6), the templates
no longer provide a sound basis for the estimation.
),
both approaches offer high selection precision and low
ranking order error. The results are mixed when the similarity ranges
from 0.75 to 0.84. The mean-based approach reaches its
best performance in precision (0.73), whereas the
histogram-based approach yields its
highest ranking order error (5.55). When the similarity is below 0.75,
the performance of mean-based approach is poor. However, the
histogram-based approach continues to offer
good performance. We believe the good performance of
the histogram-based approach within this similarity range
is due to the partitioning, which eliminates more irrelevant images.
We also observed that when the similarity between the query
and the template becomes low (generally below 0.6), the templates
no longer provide a sound basis for the estimation.
We now analyze the impact of relevance interval offset on the performance of the histogram-based ranking algorithm. Figures 11 and 12 show the test results with various offsets. We notice the selection precision reaches the highest at 0.10, whereas ranking order error is the lowest at 0.06.
We believe that an ideal offset should be as small as possible, while still includes the majority of relevant images. Different methods used in calculating the similarity rates and different image types may result in different offset values. We have found that, for our test images, an offset value of 0.06 seems to be appropriate.
![[IMG]](pvalueoff.gif)
Figure 11. P value for the different interval offsets.
![[IMG]](svalueoff.gif)
Figure 12. S value for the different interval offsets.
Based on the above analysis, the histogram-based approach offers better performance than the mean-based approach. The normal distribution requirement of the mean-based approach limits its use on databases with a large number of images similar to the template. The histogram-based approach is suitable for all databases.
Both ranking approaches perform best when the query is matched with a single template and when the similarity between the query and template is high. The histogram-based approach performs significantly better than the mean-based approach for queries matched with a single template. The histogram-based approach also outperforms mean-based approach for queries matched with multiple templates.
We also recommend a threshold of 0.6 to be used by the metaserver for creating a new template. Comparing to the given query, if none of the existing templates have a similarity greater than 0.6, than the metaserver will have the option to create a new template for the query.
Note that the histogram-based approach requires higher storage in the metaserver than the mean-based approach. The mean-based approach only requires a few statistics data (i.e., number of samples, mean and variance) for each database and template pair. The histogram-based approach requires the storage of the histograms for all partitions that are associated with each database and template pair. However, the storage requirement of the histogram-based approach can be cut down by only storing the portion of the histogram that covers the similarity rates of interest. In our test system, we store the portion of the histogram that covers similarity rates ranging from 1.0 to 0.50, since we are only interested in the similarity ranging from 0.95 to 0.65.
We have introduced a histogram-based ranking algorithm that, in addition to our previous proposed mean-based ranking approach, addresses the problem of determining the relevance of database sites to visual queries based on visual content. This is achieved by abstracting the visual information in images of databases through templates in a metadatabase and capturing the statistical features of the similarity value distributions of images as indices to database references. The selection of relevant databases is achieved by indexing of the metadatabase and a metaserver that uses the visual similarity of the query to the stored templates to rank the databases associated with the templates. The database selection mechanism has been implemented as a metaserver. The effectiveness of the two approaches have been demonstrated through extensive experiments.