![\begin{figure} \vspace{-5mm} \begin{center} \leavevmode \resizebox {\column... ...cs[0in,0in][9.75in,9.75in]{visualq.ps}} \end{center} \vspace{-10mm}\end{figure}](acmmm97img1.gif) |
Shih-Fu Chang - William Chen - Horace J. Meng - Hari Sundaram - Di Zhong
Dept. of Electrical Engineering
Columbia University
New York New York 10027.
The rapidity with which digital information, particularly video, is being generated, has necessitated the development of tools for efficient search of these media. Content based visual queries have been primarily focussed on still image retrieval. In this paper, we propose a novel, real-time, interactive system on the Web, based on the visual paradigm, with spatio-temporal attributes playing a key role in video retrieval. We have developed algorithms for automated video object segmentation and tracking and use real-time video editing techniques while responding to user queries. The resulting system performs well, with the user being able to retrieve complex video clips such as those of skiers, baseball players, with ease.
The ease of capture and encoding of digital images has caused a massive amount of visual information to be produced and disseminated rapidly. Hence efficient tools and systems for searching and retrieving visual information are needed. While there are efficient search engines for text documents today, there are no satisfactory systems for retrieving visual information.
Content-based visual queries (CBVQ) has emerged as a challenging research area in the past few years [Chang 97], [Gupta 97]. While there has been substantial progress with the presence of systems such as QBIC [Flickner 95], PhotoBook [Pentland 96], Virage [Hamrapur 97] and VisualSEEk [Smith 96] most systems only support retrieval of still images. CBVQ research on video databases has not been fully explored yet. We propose an advanced content-based video search system with the following unique features:
Specifically, we propose to develop a novel video search system which allows users to search video based on a rich set of visual features and spatio-temporal relationships. Our objective is to investigate the full potential of visual cues in object-oriented content-based video search. While the search on video databases ought to necessarily incorporate the diversity of the media (video, audio, text captions) our research will complement any such integration.
We will present the the visual search paradigm in section 2, elaborate on the system overview in section 3, describe video objects and our automatic video analysis techniques in sections 4-5, discuss the matching criteria and query resolution in sections 7-8 and finally present some preliminary evaluation results in section 9.
|
The fundamental paradigm under which VideoQ operates is the visual one. This implies that the query is formulated exclusively in terms of elements having visual attributes alone. The features that are stored in the database are generated from an automatic analysis of the video stream. There is no information present in the query loop that emanates from the captions, textual annotations or the audio stream. Many retrieval systems such as PhotoBook [Pentland 96], VisualSEEk [Smith 96] and Virage [Hamrapur 97] share this paradigm, but only support still image retrieval. While QBIC [Flickner 95] is visual, it is not exclusively so as the images have been manually annotated allowing for keyword searches on the database.
Video retrieval systems should evolve towards a systematic integration of all available media such as audio, video and captions. While video engines such as [Hauptmann 95], [Hamrapur 97], [Shahraray 95], [Mohan 96] attempt at such an integration, much research on the representation and analysis of each of these different media remains to be done. Those that concentrate on the visual media alone fall into two distinct categories:
In the context of image retrieval, examples of QBE systems include QBIC, PhotoBook, VisualSEEk, Virage and FourEyes [Minka 96]. Examples of sketch based image retrieval systems include QBIC, VisualSEEk, [Jacobs 95], [Hirata 92] and [Del Bimbo 97]. These two different ways of visually searching image databases may also be accompanied by learning and user feedback [Minka 96].
Query by example systems work under the realization that since the ``correct'' match must lie within the database, one can begin the search with a member of the database itself. With the hope that one can guide the user towards the image that he likes over a succession of query examples. In QBE, one can use space partitioning schemes to precompute hierarchical groupings, which can speed up the database search [Minka 96]. While the search speeds up, the groupings are static and need recomputation every time a new video is inserted into the database. QBE in principle, is easily extensible to video databases as well, but there are some drawbacks. Video shots generally contain a large number of objects, each of whom are described by a complex multi-dimensional feature vector. The complexity arises partly due to the problem of describing shape and motion characteristics.
Sketch based query systems such as [Hirata 92] compute the correlation between the sketch and the the edge map of each of the images in the database, while in [Del Bimbo 97], the authors minimize an energy functional to achieve a match. In [Jacobs 95], the authors compute a distance between the wavelet signatures of the sketch and each of the images in the database.
What makes VideoQ powerful is the idea of an animated sketch to formulate the query. In an animated sketch, motion and temporal duration are the key attributes assigned to each object in the sketch in addition to the usual attributes such as shape, color and texture. Using the visual pallette, we sketch out a scene by drawing a collection of video objects. It is the spatio-temporal ordering (and relationships) of these objects that fully define a scene. This is illustrated in Figure 1.
While we shall extensively employ this paradigm, some important observations
are to be kept in mind. The visual paradigm works best when there are only
a few dominant objects in the video with simply segmented backgrounds![]() .
It will not work well if the user is interested in video sequences that
are simple to describe, but are hard to sketch out. For example, a video
shot of a group of soldiers marching, shots of a crowd on the beach etc.
It will also not work well when the user is interested in a particular
semantic class of shots: he might be interested in retrieving that news
segment containing the anchor person, when the news anchor is talking about
Bosnia.
.
It will not work well if the user is interested in video sequences that
are simple to describe, but are hard to sketch out. For example, a video
shot of a group of soldiers marching, shots of a crowd on the beach etc.
It will also not work well when the user is interested in a particular
semantic class of shots: he might be interested in retrieving that news
segment containing the anchor person, when the news anchor is talking about
Bosnia.
VideoQ is a Web based video search system, where the user queries the system using animated sketches. An animated sketch is defined as a sketch where the user can assign motion to any part of the scene.
VideoQ which resides on the Web, incorporates a client-server architecture. The client (a java applet) is loaded up into a web browser where the user formulates (sketches) a query scene as a collection of objects with different attributes. Attributes include motion, spatio-temporal ordering, shape and the the more familiar attributes of color and texture.
The query server contains several feature databases, one for each of the individual features that the system indexes on. Since we index on motion, shape, as well as color and texture, we have databases for each of these features. The video shot database is stored as compressed MPEG streams.
Once the user is done formulating the query, the client sends it over the network to the query server. There, the features of each object specified in the query are matched against the features of the objects in the database. Then, lists of candidate video shots are generated for each object specified in the query. The candidate lists for each object are then merged to form a single video shot list. Now, for each of these video shots in the merged list, key-frames are dynamically extracted from the video shot database and returned to the client over the network. The matched objects are highlighted in the returned key-frame.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...ics[0in,0in][6.25in,2.5in]{system.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img2.gif) |
The user can interactively view these matched video shots over the network by simply clicking on the the key-frame. Then, in the backend, the video shot corresponding to that key frame is extracted in real time from the video database by ``cutting'' out that video shot from the database. The video shots are extracted from the video database using basic video editing schemes [Meng 96] in the compressed domain. The user needs an MPEG player in order to view the returned video stream.
Since the query as formulated by the user in the VideoQ system comprises of a collection of objects having spatio-temporal attributes, we need to formalize the definition of a video object.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...n][5.25in,4.25in]{vidobj-features.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img3.gif) |
We define a region to be a contiguous set of pixels that is homogeneous
in the the features that we are interested in (i.e texture, color, motion
and shape). A video object is defined as a collection of video regions
which have been grouped together under some criteria across several frames.
Namely, a video object is a collection of regions exhibiting consistency![]() across several frames in at least one feature. For example a shot of a
person (the person is the ``object'' here) walking would be segmented into
a collection of adjoining regions differing in criteria such as shape,
color and texture, but all the regions may exhibit consistency in their
motion attribute. As shown in Figure 3,
the objects themselves may be grouped into higher semantic classes.
across several frames in at least one feature. For example a shot of a
person (the person is the ``object'' here) walking would be segmented into
a collection of adjoining regions differing in criteria such as shape,
color and texture, but all the regions may exhibit consistency in their
motion attribute. As shown in Figure 3,
the objects themselves may be grouped into higher semantic classes.
The grouping problem of regions is an area of ongoing research and for the purposes of this paper, we restrict our attention to regions only. Regions may be assigned several attributes, such as color, texture, shape and motion.
In the query interface of VideoQ, the set of allowable colors is obtained by uniformly quantizing the HSV color space. The Brodatz texture set is used for assigning the textural attributes to the various objects. The shape of the video object can be an arbitrary polygon along with ovals of arbitrary shape and size. The visual palette allows the user to sketch out an arbitrary polygon with the help of the cursor, other well known shapes such as circles, ellipses and rectangles are pre-defined and are easily inserted and manipulated.
Motion is the key object attribute in VideoQ. The motion trajectory interface (Figure 4) allows the user to specify an arbitrary polygonal trajectory for the query object. The temporal attribute which defines the overall duration of the object, which can either be intuitive (long, medium or short) or absolute (in seconds).
Since VideoQ allows users to frame multiple object queries, the user has the flexibility of specifying the overall scene temporal order by specifying the ``arrival'' order of the various objects in the scene. The death order (or the order in which they disappear from the video) depends on the duration of each object).
Another attribute related to time is the scaling![]() factor, or the rate at which the size of the object changes over the duration
of the objects existence. Additional global scene attributes include the
specification of the (perceived) camera motion like panning or zooming.
The VideoQ implementation of the temporal attributes is shown in figure
4.
factor, or the rate at which the size of the object changes over the duration
of the objects existence. Additional global scene attributes include the
specification of the (perceived) camera motion like panning or zooming.
The VideoQ implementation of the temporal attributes is shown in figure
4.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...phics[0in,0in][5.5in,1in]{temporal.ps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img4.gif) |
Prior to the actual query, the various features need to be weighted in order to reflect their relative importance in the query (refer to Figure 1). The feature weighting is global to the entire animated sketch; for example, the attribute color, will have the same weight across all objects. The final ranking of the video shots that are returned by the system is affected by the weights that the user has assigned to various attributes.
The entire video database is processed off-line. The individual videos are decomposed into separate shots, and then within each shot, video objects are tracked across frames.
Prior to any video object analysis, the video must be split up into ``chunks'' or video shots. Video shot separation is achieved by scene change detection. Scene change are either abrupt scene changes or transitional (e.g. dissolve, fade in/out, wipe). [Meng 95] describes an efficient scene change detection algorithm that operates on compressed MPEG streams.
It uses the motion vectors and Discrete Cosine Transform coefficients from the MPEG stream to compute statistical measures. These measurements are then used to verify the heuristic models of abrupt or transitional scene changes. For example, when a scene change occurs before a B frame in the MPEG stream, most of the motion vectors in that frame will point to future reference frame. The real-time algorithm operates directly on the compressed MPEG stream, without complete decoding.
The global motion (i.e. background motion) of the dominant background
scene is automatically estimated using the six parameter affine model [Sawhney
95]. A hierarchical pixel-domain motion estimation method [Bierling
88] is used to extract the optical flow. The affine model of the global
motion is used to compensate the global motion component of all objects
in the scene![]() .
The six parameter model:
.
The six parameter model:
![]() =
ao +a1 x+a2
y
=
ao +a1 x+a2
y
![]() =
a3 +a4 x+a5
y
=
a3 +a4 x+a5
y
where, ai are the affine parameters, x,y
are the pixel coordinates, and ![]() ,
,
![]() are the pixel displacements at each pixel.
are the pixel displacements at each pixel.
Classification of global camera motion into modes such as zooming or panning is based on the global affine estimation. In order to detect panning, a global motion velocity histogram is computed along eight directions. If there is dominant motion along a particular direction, then the shot is labeled as a panning shot along that direction.
In order to detect zooming, we need to first check if the average magnitude of the global motion velocity field and two affine model scaling parameters (a1 and a5) satisfy certain threshold criteria.
When there is sufficient motion, and a1 and a5 are both positive, then the shot is labeled as a ``zoom-in'' shot and if they are both negative then the shot is labeled as a ``zoom-out''.
Our algorithm for segmentation and tracking of image regions based on the fusion of color, edge and motion information in the video shot. The basic region segmentation and tracking procedure is shown in Figure 5. The projection and segmentation module is the module where different features are fused for region segmentation and tracking.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...phics[0in,0in][4.5in,4in]{reg-seg.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img7.gif) |
Color is chosen as the major segmentation feature because of its consistency
under varying conditions. As boundaries of color regions may not be accurate
due to noise, each frame of the video shot is filtered before color region
merging is done. Edge information is also incorporated into the segmentation
process to improve the accuracy. Optical flow is utilized to project and
track color regions through a video sequence.
The optical flow of current frame n is derived from frame n and n+1 in the motion estimation module using a hierarchical block matching method [Bierling 88]. Given color regions and optical flow generated from above two processes, a linear regression algorithm is used to estimate the affine motion for each region. Now, color regions with affine motion parameters are generated for frame n, which will the be tracked in the segmentation process of frame n+1.
![\begin{figure} \vspace{-5mm} \begin{center} \leavevmode \resizebox {\column... ...cs[0in,0in][3.5in,4.5in]{proj-seg.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img8.gif) |
Now we discuss the projection and segmentation module [Zhong
97] (see Figure 6). In the first step,
the current frame (i.e. frame n) is quantized in a perceptually
uniform color space (e.g., CIE LUV space). Quantization palettes can be
obtained by a uniform quantizer or clustering algorithms (e.g., self-organization
map). After quantization, non-linear median filtering is used to eliminate
insignificant details and outliers in the image while preserving edge information.
In the meanwhile, edge map of frame n is extracted using
edge detectors (e.g. Canny edge detector).
For the first frame in the sequence, the system will go directly to intra-frame segmentation. For intermediate frames, as region information is available from frame n-1, an interframe projection algorithm is used to track these regions. All regions in frame n-1 are projected into frame n using their affine motion estimates. For every pixel in frame n that is covered by regions projected from the previous frame, we label it as belonging to the region to which it is closest in the CIE-LUV space. If a pixel is not covered by any projected region, then it remains unlabeled.
The tracked regions together with un-labeled pixels are further processed by an intra-frame segmentation algorithm. An iterative clustering algorithm is adopted: two adjoining regions with the smallest color distance are continuously merged until the difference is larger than a given threshold. Finally, small regions are merged to their neighbors by a morphological open-close algorithm. Thus, the whole procedure generates homogeneous color regions in frame n while tracking existing regions from frame n-1.
The edge map is used to enhance color segmentation accuracy [Zhong
97]. For example, regions clearly separated by long edge lines will
not be merged with each other. Short edge lines which are usually inside
one color region will not affect the region merging process.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...udegraphics[0in,0in][10in,3in]{cnn.ps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img9.gif) |
Figure 7 shows segmentation results with two sequences. In both cases, the top row shows original sequence and the second row shows a subset of automatically segmented regions being tracked. Tracked regions are shown with their representative (i.e. average) colors. Experiments show that our algorithm is robust for the tracking of salient color regions under different circumstances, such as multiple objects, fast or slow motion and instances of regions being covered and uncovered
Once each object in the video shot has been segmented and tracked, we then compute the different features of the object and store them in our feature library. For each object we store the following features:
The resulting library is a simple database having a {attribute, value} pair for each object. Creating a relational database will obviously allow for more complex queries to be performed over the system as well as decrease the overall search time. The issue of the structure of the database is an important one, but was not a priority in the current implementation of VideoQ.
The nature of the metric, plays a key role in any image or video retrieval system. Designing good metrics is a challenging problem as it often involves a tradeoff between computational complexity of the metric and the quality of the match. For it is not enough to be able to locate images or videos that are close under a metric, they must be perceptually close to the query.
While we employ well accepted metrics for color, texture and shape, we have designed new metrics to exploit the spatio-temporal information in the video.
A motion trail is defined to be the three dimensional trajectory of
a video object. It is represented by a sequence ![]() ,the
three dimensions comprising of the two spatial dimensions x,y
and the temporal dimension t (normalized to the frame number.
The frame rate provides us with the true time information). Prior techniques
to match motion [Dimitrova 94], have used
simple chain codes or a B-spline to represent the trajectory, without completely
capturing the spatio-temporal characteristic of the motion trail.
,the
three dimensions comprising of the two spatial dimensions x,y
and the temporal dimension t (normalized to the frame number.
The frame rate provides us with the true time information). Prior techniques
to match motion [Dimitrova 94], have used
simple chain codes or a B-spline to represent the trajectory, without completely
capturing the spatio-temporal characteristic of the motion trail.
The user sketches out the trajectory as a sequence of vertices in the
x-y plane. In order for him to specify motion trail
completely he must specify the duration of the object in the video shot.
The duration is quantized (in terms of the frame rate![]() )
into three levels: long, medium and short. We compute the entire trail
by uniformly sampling the motion trajectory based on the frame rate.
)
into three levels: long, medium and short. We compute the entire trail
by uniformly sampling the motion trajectory based on the frame rate.
We develop two major modes of matching trails:
| |
(1) |
where, the subscripts q and t refer to the
query and the target trajectories respectively and the index i
runs over the the frame numbers![]() .
Since in general, the duration of the query object will differ from that
of the objects in the database, there are some further refinements possible.
.
Since in general, the duration of the query object will differ from that
of the objects in the database, there are some further refinements possible.
Let us briefly describe the distance metrics used in computing the distances in the other feature spaces.
| |
(2) |
where, Cd is the weighted Euclidean color distance in the CIE-LUV space and the subscripts q and t refer to the query and the target respectively.
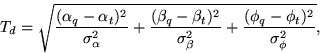 |
(3) |
where, ![]() and
and ![]() refer to the coarseness, contrast and the orientation respectively and
the various
refer to the coarseness, contrast and the orientation respectively and
the various ![]() refer to the variances in the corresponding features.
refer to the variances in the corresponding features.
| |
(4) |
where, ![]() and
and ![]() are the eigenvalues along the principal axes of the object (their ratio
is the aspect ratio).
are the eigenvalues along the principal axes of the object (their ratio
is the aspect ratio).
| |
(5) |
where, Aq,t refer to the percentage areas of the query and target respectively.
The total distance is simply the weighted sum of these distances, after the dynamic range of each metric has been normalized to lie in [0,1]. i.e
| |
(6) |
where ![]() is the weight assigned to the particular feature and Di
is the distance in that feature space.
is the weight assigned to the particular feature and Di
is the distance in that feature space.
Using these feature space metrics and the composite distance function, we compute the composite distance of each object in the database with the each object in the query. Let us now examine how we generate candidate video shots, given a single and multiple objects as queries. An example of an single object query along with the results (the candidate result) is shown in Figure 1.
The search along each feature of the video object produces a candidate
list of matched objects and the associated video shots. Each candidate
list can be merged by a rank threshold or a feature distance threshold.
Then, we merge the candidate lists, keeping only those that appear on the
candidate list for each feature. Next, we compute the global weighted distance
Dg, and then sort the merged list based on this
distance. A global threshold is computed (based on the individual thresholds
and additionally modified by the weights) which is then used to prune the
object list. This is schematically shown is Figure 8.
Since there is a video shot associated with each of the objects in the
list, we return the key-frames of the corresponding video shots to the
user.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...cs[0in,0in][6.5in,2.75in]{single.eps} } \end{center} \vspace{-20pt}\end{figure}](acmmm97img25.gif) |
When the query contains multiple video objects, we need to merge the results of the individual video object queries. The final result is simply an logical intersection of all the results of the individual query objects. When we perform a multiple object query in the the present implementation, we do not use the relative ordering of the video objects in space as well in time. These additional constraints could be imposed on the result by using the idea of 2D strings [Chang 87], [Shearer 97], [Smith 96] (discussed in 10.3).
Evaluating the performance of video retrieval systems is still very much an open research issue [Chang 97]. There does not exist a standard video test set to measure retrieval performance nor standard benchmarks to measure system performance. This is partly due to the emerging status of this field. To evaluate VideoQ, we use two different approaches. First, we extend the standard precision-recall metrics in information retrieval. Although we acknowledge several drawbacks of this classical metric, we include it here simply as a reference. Another type of metric measures the effort and cost required to locate a particular video clip that a user has in mind or one that the user may have previously browsed in the database.
In our experimental setup, we have a collection of 200 video shots, categorized into sports, science, nature, and history. By applying object segmentation and tracking algorithms to the video shots, we generated a database of more than 2000 salient video objects and their related visual features.
To evaluate our system, precision-recall metrics are computed. Precision-recall metrics characterize the retrieval effectiveness of the system. While the VideoQ system is composed of many parts, such as scene cut detection, object segmentation and tracking, and feature selection and matching, precision-recall metrics measure how well the system as a whole performs. Performance is based solely on how close the returned results compare with the ground truth.
Before each sample query, the user establishes a ground truth by choosing a set of relevant or ``desired'' video shots from the database. For each sample query shown in Figure 9, a ground truth is established by choosing all the relevant video shots in the database that have corresponding features. The sample query returns a list of candidate video shots, and precision-recall values are calculated according to equations 9, 10. A precision-recall curve is generated by increasing the size of the return list and computing precision-recall values for each size.
Recall = Retrieved and Relavant/All Relavant in Database
Precision = Retrieved and Relavant/Number Retrieved
where, the relevant video shots are predefined by the ground truth database.
Four sample queries were performed as shown Figure 9. The first sample query specifies a skin-colored, medium-sized object that follows a motion trajectory arcing to the left. The ground truth consisted of nine video shots of various high jumpers in action and brown horses in full gallop. The return size is increased from 1 to 20 video shots, and a precision-recall curve is plotted in Figure 10 (a).
An overlay of the four precision-recall curves is plotted in Figure 10. For an ideal system, the precision-recall curve is a horizontal line with precision value of 1.0 as recall ranges from 0.0 to 1.0. For normal systems, the precision-recall curve remains relatively flat up to a certain recall value, after which the curve slopes downward. We note that a breakpoint as the point where the number of retrieved video shots equals the number of relavant video shots. The breakpoints of the four precision-recall curves are marked with a cross. The distance of the breakpoint from 1.0 (the optimal recall point) indicates how effective that particular query was; the farther the distance of breakpoint, the less optimal the performance.
Both sample queries (a) and (c) performed well in Figure 10. In both cases, the motion trajectories were well-defined, not easily confused with camera motion. The sample query (b), however, did not perform as well. One reason is that, in some video shots, the background objects were not properly compensated by the global motion compensation algorithm and were treated as foreground objects. Since the video database contains many shots where the camera is panning from right to left, those same background objects were indexed with left/right motion trajectories. The average precision-recall curve is also calculated and plotted in Figure 11.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...[0in,0in][4in,4.25in]{pr-queries.eps} } \end{center} \vspace{-20pt}\end{figure}](acmmm97img26.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...0in][7.25in,5.75in]{fourprecision.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img27.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...0in,0in][7.25in,5.75in]{precision.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img28.gif) |
Two benchmarks are used to evaluate how efficiently the system uses its resources to find the correct video shot. Query frequency measures how many separate queries are needed to get a particular video shot in the return list. Bandwidth measures how many different false alarms are returned before obtaining the correct video shot in the return list.
A randomly generated target video shot, shown in Figure 12 (b), is chosen from the database. In order to find this video shot, we query the system, selecting a combination of objects, features, and feature weights. The total number of queries to get this video shot is recorded. By varying the size of the return list, the query frequency curve is generated.
Each query returns a list of video shots from an HP 9000 server over the network to a client. The video shot is actually represented by a 88x72 key frame. In many cases, a series of queries were needed to reach a particular video shot. The number of key frames that were returned are totaled. Repeat frames are subtracted from this total since they are stored in the cache and not retransmitted over the network. Conceptually bandwidth is proportional to the total number of key frames transmitted. Therefore the bandwidth is recorded and by varying the size of the return list, the bandwidth curve is generated.
Twenty target video shots, similar to those in Figure 12, are randomly selected. For each target video shot, sample queries are performed, and query frequency and bandwidth curves are generated by varying the return size from 3 to 18 video shots.
The query frequency curve in Figure 13 shows that a greater number of queries are needed for small return sizes. On average for a return size of 14, only two queries are needed to reach the desired video shot.
In Figure 14, the bandwidth curve linearly decreases as return size decreases. For small return sizes, many times ten or more queries failed to place the video shot within the return list. These ``failed'' videos, shown in Figure 15, were simply discarded in this case. In Figure 16, we compensate for these failed queries by applying a heuristic to penalize the returned videos. Once this was done, the average bandwidth was recalculated in Figure 16, which shows that a medium return size requires the least amount of bandwidth.
The system performed better when it was provided with more information. Multiple object queries proved more effective than single object queries. Also, objects with a greater number of features, such as color, motion, size, and shape, performed better than those with just a few features. It is also important to emphasize that certain features proved more effective than others. For example, motion was the most effective, followed by color, size, shape and texture.
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...phics[0in,0in][8in,9.4in]{samples.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img29.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...s[0in,0in][7.25in,5.75in]{queries.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img30.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...0in,0in][7.25in,5.75in]{bandwidth.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img31.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...cs[0in,0in][7.25in,5.75in]{failed.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img32.gif) |
![\begin{figure} \begin{center} \leavevmode \resizebox {\columnwidth}{!}{\incl... ...in,0in][7.25in,5.75in]{bandwidth2.eps}} \end{center} \vspace{-20pt}\end{figure}](acmmm97img33.gif) |
While the results section (Section 9) demonstrates that VideoQ works well, there are other issues that need to be addressed. This section contains a brief overview of the issues that we are currently working on.
Automatic region grouping, is an open problem in computer vision, and in spite of decades of research, we are still far from completely a automated technique that works well on unconstrained data. Nevertheless, the segmented results, need to be further grouped in order for us to prune the search as well search at a higher semantic level. Also good region grouping is needed avoid over-segmentation of the video shot.
One of the biggest challenges with using shape as a feature is to be
able to represent the object while retaining a computationally efficient
metric to compare two shapes. The complexity of matching two arbitrary
N point polygons is ![]() [Arkin 91].
[Arkin 91].
One approach is to use geometric invariants to represent shape [Mundy 92], [Karen 94], [Lei 95]. These are invariants on the coefficients of the implicit polynomial used to represent the shape of the object. However, these coefficients need to be very accurately calculated as the representation (that of implicit polynomials) is very sensitive to perturbations. Additionally, generating these coefficients is a computationally intensive task.
We are currently extending the work done on VisualSEEk [Smith 96] on 2-D strings [Chang 87] in order to effectively constrain the query results. There has been work using modified 2-D strings as a spatial index into videos [Arndt 89], [Shearer 97].
For video, 2-D strings can be extended to a sequence of 2D-strings or a 2D-string followed by a sequence of change edits [Shearer 97]. Building on these observations we propose two efficient methods for indexing spatio-temporal structures of segmented video objects.
Video search in large archives is an emerging research area. Although integration of the diverse multimedia components is essential in achieving a fully functional system, we focus on exploiting visual cues in this paper. Using the visual paradigm, our experiments with VideoQ show considerable success in retrieving diverse video clips such as soccer players, high jumpers and skiers. Annotating video objects with motion attributes and good spatio-temporal metrics have been the key issues in this paradigm.
The other interesting and unique contributions include developing a fully automated video analysis algorithm for object segmentation and feature extraction, a java-based interactive query interface for specifying multi-object queries, and the content-based visual matching of spatio-temporal attributes.
Extensive content analysis is used to obtain accurate video object information. Global motion of the background scene is estimated to classify the video shots as well as to obtain the local object motion. A comprehensive visual feature library is built to incorporate most useful visual features such as color, texture, shape, size, and motion. To support the on-line Web implementation, our prior results in compressed-domain video shot segmentation and editing are used. Matched video clips are dynamically ``cut'' out from the MPEG stream containing the clip without full decoding of the whole stream.
As described earlier, our current work includes region grouping, object classification, more accurate shape representation, and support of relative spatio-temporal relationships. An orthogonal direction addresses the integration of the video object library with the natural language features to fill the gap between low-level visual domain and the high-level semantic classes.