![[IMG]](Image20.gif)
Figure 1. Trade-off between round length and time between services for scheduling algorithms.
Crowne Plaza Hotel, Seattle, USA
This paper presents a novel data placement and retrieving scheme or real-time multimedia stream playback via a scalable storage system. The multimedia streams are contiguous data packets which may be representing video, audio, or other media be retrieved simultaneously from a storage system on a real-time and on-demand basis. The major challenge in implementing the system is the support of simultaneously retrieving a big number of streams from a large-capacity storage system. This bottleneck comes from the seeking delay caused by the random movement of disk head in the storage under multiple stream requests. The proposed scheme efficiently reduces the seeking time by a very simple placement method and a retrieval scheduler and, in the mean time, continuous playback of multiple real-time streams and a scalable storage capacity are both achieved. Performance valuation of the proposed scheme is provided through theoretical analysis and experimental measure.
Data placement, Multimedia system, Storage system.
The design of a multimedia server is emerging as a key technology in the trend toward inter-active multimedia services such as the video-on- demand (VoD), karaoke-on-demand (KoD), or distance learning. An efficient media server primarily acts as an engine reading multimedia bit streams from the disk storage and pumping these to the clients at the proper delivery rate. One of the most important criteria in designing these interactive multimedia systems is the maximum number of multimedia streams that can be simultaneously supported. A media server must be able to timely pump the media bit streams while still supporting a large number of simultaneous clients retrieving the streams from the media server.
The media streams are digital bitstreams. Each media stream should be delivered at a quality-of-service constraints, i.e., a proper average bit-rate or delay jitter limitation. There are several bottlenecks which limit the stream pumping capability, such as storage I/O, network bandwidth, and CPU processing overhead. In this paper, we focus on the storage I/O design for optimizing the multimedia stream pumping. In building such an media server system to serve multimedia clients from a set of disks, the major parameter that constrains the number of active clients is the data retrieval method that read the streams out of the disk set. To achieve the high data pumping rate requirement, the RAID (Redundant Array of Inexpensive Disks) systems have been used [1], [2]. . In [3], it shows the performance improvement by using data stripping on an array of disk drives is still limited since the random-access file placement is still used on each stripped disk drive and there exists unavoidable overhead, i.e., the disk seeking delay and the SCSI bus contention.
To reduce the seeking overhead, the disk scheduling, data placement, and admission control must be carefully designed. Disk scheduling algorithms, such as first come first served, shortest seek time first, Scan, and others, have been used to reduce seek time and rotational latency, to achieve high throughput, and to provide fair access to each stream. However, these algorithms can not satisfy the real-time constraints. For example, the Scan or elevator algorithm scans the disk head back and forth by limiting the amount of backtracking. The disk can retrieve the required data blocks in such a way as to significantly reduce the seek latencies. For video-on-demand files, there is little locality between disk access locations for different streams. Even for the same media stream, the probability of two or more clients accessing the same media stream within a short time period is very difficult to predict. Therefore, the Scan algorithm can not satisfy the real- time constraints.
Scheduling of the disk head based solely on earliest deadline first (EDF) algorithm, perhaps the best known algorithm for real-time scheduling of tasks with deadlines, is likely to introduce excessive seek time and rotational latency, and to yield poor server resource utilization. For real-time applications, the Scan-EDF scheduling algorithm was proposed in [4]. Scan-EDF services the requests with earliest deadlines first. However, when there are lots of requests having the same deadline, as in the video-on-demand systems, their respective blocks are essentially accessed with the Scan algorithm and the Scan-EDF algorithm is reduced to Scan only.
On the other hand, the server can retrieve a media stream block sequence of arbitrary length for each stream in rounds. The simplest disk scheduling algorithm for each round is the round-robin algorithm. The major drawback in the round-robin scheduling algorithm is that it does not exploit the relative positions of the media blocks being retrieved during a round. An out of sorts sequence in each round can yield unpredictable long seek latency. Therefore, the data-placement algorithms should be considered in conjunction with the disk scheduling algorithms.
In the disk storage subsystem, sequential data access can have approximately two times higher throughput (with block size << 100 KB per read) than the random data access. However, when a lot of users simultaneously access the media server, the interleaving media stream retrievals make the stream pumping being eventually a random storage access process. Therefore in this paper, a novel media stream retrieving scheme called, Virtually Sequential Pumping (VSP) is proposed for the media server. In the proposed media server, data are stripped and placed onto disks in a virtually sequential order. Multiple retrieval schedulers are then used to parallelly and virtual-sequentially pump the media streams from the media server. With the proposed VSP scheme, the media server can then pump numerous media streams for providing services to a large number of clients.
The retrieval scheduling and the media stream placement are the two major components that affect the media server's stream pumping throughput, while the admission control is used to maintain the quality-of- service. In this section, the schemes for retrieving the media streams from the storage devices are discussed.
In the round-robin algorithm, the streams are serviced in fixed order across rounds such that the maximum latency between retrieval times of streams' successive requests is bounded by one round's period. For the Scan algorithm, a stream is serviced in the order depending on the relative placement of blocks being retrieved. Therefore, a stream can be serviced at the beginning of one round and at the end of next round. The round latency has several implications for data transfer delay and buffer requirements. For round-robin, after all blocks from the stream's first request have been retrieved, the successive data pumping can be initiated. To prevent pumping starvation, only enough buffer space to satisfy data consumption for one round is needed. While in Scan, enough buffer space to satisfy data consumption for nearly two rounds is required.
Compared to the round-robin algorithm, the rounds are shorter in the Scan algorithm but latency between successive retrievals in any specific stream may be longer. The sub-grouping algorithm partitions each round into groups. Each stream is assigned to one of the groups and the groups are served in a fixed order in each round. The Scan algorithm is used in each group. If all streams are assigned to the same group, it is Scan scheme. It is round-robin, when each stream is assigned to its own unique group. Figure 1 shows the worst-case latency between successive retrievals in any specific stream using these schemes.
Real-time constraint is an important parameter in designing a video server such that nearly all video servers process the stream requests in rounds. For an algorithm to have the buffer-conserving [5] property (referred to as work-ahead-augmenting in [6]), data retrieval rate should never lags consumption rate and there is never a net decrease in the amount of buffered data, on a round-by-round basis. An non buffer-conserving algorithm, which is more complex, allow data retrieval rate falling behind consumption rate in one round and compensate for it in a later round. The buffer-conserving is a sufficient condition for preventing starvation. Because, if enough bit stream is prefetched to meet the consumption requirements of the longest possible round and if each round thereafter is buffer-conserving, there never is a starvation. As the round length depends on the number of blocks retrieved for each stream, to minimize round length, the number of blocks retrieved for each stream during each round should be proportional to the stream's consumption rate.
Figure 1. Trade-off between round length and time between services for scheduling algorithms.
Naturally, a server must manage its buffers to leave sufficient free space for the next reads to be performed. The buffer size can approximate the size of the maximum required retrieve when using a FIFO, contiguous files, and round-robin scheduling. The Scan strategy requires at least a double-buffered scheme and each buffer is the size of the maximum read. When files are not stored contiguously, an extra intrastream seek might be required that means the data to be retrieved is split across two blocks. Three buffers structure can be used for this problem, in which the only time the data can not be read is when at least two buffers are full. In [5], there are some solutions with fewer than three buffers.
A media stream can be stored contiguously or scattered about the storage device. Contiguous bit stream are simple to implement but subject to fragmentation. In contrast, scattered placements avoid fragmentation and copying overheads. For continuous media, the choice between contiguous and scattered storing strategies relates primarily to intrastream seeks. When reading from a contiguous stream, only one seek is required to position the disk head at the start of the bit stream. On the other hand, when reading several blocks in a scattered bit stream, a seek could be incurred for each block read. Even when reading a small amount of data, it is possible that part of the data might be stored in one block and the rest in the next block, and intrastream seek incurs. If the amount read for a stream always evenly divides a block, intrastream seeks can be avoided in scattered layouts. One approach to achieve this result is to select a sufficiently large block size and read one block in each round.
If more than one block is required to prevent starvation prior to the next read, intrastream seeks are necessary. In this case, constrained placement techniques [7], which ensure the separation between successive stream blocks is bound, can be used to reduce them to a reasonable bound. This is particularly attractive when the block size must be small. However, elaborate algorithm is required to assure that separation between blocks conforms to the required constraints and a scheduling algorithm is needed to retrieve all blocks for a given stream before switching to any other stream.
In single disk configuration, disk throughput can be improved by increasing the size of the physical block. But the block size can not be increased unlimited since this would increase the logical block size and consequently lengthen startup delays and enlarge buffer space requirements per stream. If an entire media stream is stored on one disk, the number of concurrent accesses to that media stream is limited. To overcome this limitation, scattering technology should be used. The scattering can be achieved by using two techniques: stream stripping and stream interleaving. Under the RAID scheme, media stream is stripped across an array of disks and parallel access can be achieved. If the disk set is spindle synchronized and operated in lock-step parallel mode, physical sector of each disk is accessed in parallel as a large logical sector. Because access are performed in parallel, logical and physical blocks have identical access times. Therefore, the retrieve throughput is increased by the number of drives involved. In stream interleaving, the blocks are interleaved across the disk array for storage. A simple interleave pattern stores the blocks cyclically across a disk array with successive stream blocks stored on different disks. These disks are not spindle synchronized and can operate independently. Two stream retrieval methods can be used with this scheme. The one is as in the stripping model where one block is retrieved from each disk in every round. This method ensures a balanced load but requires more buffer space. The other method retrieves bit stream blocks from one of the disks for a given request in each round. In this scheme, stream retrieval is cycled through all disks and the retrieval load for each round should be balanced across the disks to maximize the throughput. The load can be balanced by interleaving the streams, in which all streams still have the same round length but each stream considering the round to begin at different time. In this method, however, stream retrievals are interleaved rather than simultaneous.
From the above analysis we see that the number of users is limited in the contiguous placement scheme, while the scattering technologies increase the throughput by introducing the concurrent access. However, in the scattering placement, the seek latency is increased. Besides, the load balancing and the buffer management should be carefully managed to maximize the throughput. Therefore, a better approach is a method which considers both the data placement and retrieval simultaneously. Partitioning each disk into multiple zones has been proposed previously to incorporate both concept [8]. However in their scheme, the disk head is scheduled back and forth so that some zones must be in different size. And the file size is required to be identical or be placed from the beginning zone of system to obtain the best parallelism. In our proposed VSP scheme, there is no such constraints. In Section 3.1, we design a virtual-sequential placement method where video data are stripped and virtual-sequentially placed onto the disks. With the designed multiple read-schedulers scheme in Section 3.2, the less seek latency, the concurrent access, the load balance, and the less buffer size can all be achieved.
When pumping the media streams, the media server should not only maximize the resource utility but also maintain the quality-of-service. Media server can offer three broad quality-of-service classes:
For deterministic service, resources should be reserved in worst-case fashion for each stream. The server must check whether buffering for existing streams is adequate to prevent starvation before admitting another service request and lengthening the round's duration [6], [9]. Instead of the server's computing the change to round length based on worst-case values, the statistical service compute it based on the statistical values. For statistical traffic, different strategies, such as dropping media blocks or dynamically vary media resolution levels, are available to resolve the missed deadline. In order to maximize the resources usage, algorithms that dynamically calculate the real-time requirements and carefully lengthen the round's duration to insert the new requests are needed. In [10], we have designed a simple architecture that can easily handle the deterministic, statistical, and best-effort traffics simultaneously and guarantee the quality-of-service (QoS). This scheme can be combined with the following new designed scheduling and placement method to pump numerous media streams to clients while guaranteeing the QoS requirements.
The parameters that constrain the number of streams supported by the media server are:
Disk seeks have four major components which are (i)acceleration (ii) constant velocity motion (iii) deceleration and (iv) head settle time. The average disk seek time is computed by dividing the sum of the time taken for all possible seeks by the number of possible seeks. The worst case seek time comes from a seek across the full disk. With suitably long seeks, acceleration, deceleration, and head settle time can be thought of as a fixed overhead. Very short seeks would take less time than this because full acceleration is not required. The observed variance between worst case and average case seek time can approach 2-to-1. For example, the average seek time and maximum seek time of the Seagate ST32550 disk are 8.5ms and 18ms, respectively.
Meanwhile, a track near the outer edge of a disk is longer than one near the inner edge, so there is a greater storage capacity in the outer tracks. For example, the Seagate ST31250/ST32550 disk changes from 51450 to 74900 bytes per track from inner to outer tracks. With constant rotational velocity, the bandwidth obtainable from the outer regions is larger than from the inner ones.
The amount of data transferred in each disk read also affects the performance. For example, for the Seagate ST31250, experimental data show that for sequential read the throughput equals 7MB/s when the read block size is 100KB to 500kB. For random access, the throughput equals 4.8MB/s when block size is 500KB and the throughput drops to 2.8MB/s when block size is 100KB. In sequential read, only one seek operation is required. The results shows that disk overhead can be minimized by transfer of large amounts of data at a time. Under that, a higher proportion of time is spent transferring data, and a lower proportion is spent doing seeks. Any scheme to maximize the number of supported streams should carefully handle the stream pumping bandwidth and seek times. In order to maximize the number of supported streams, the design of server scheduler must ensure that, over some bound (short) interval of time, the average case bandwidth and seek times are always guaranteed approximately. Thus, in the designed media server, the disks are first divided into equal bandwidth zones and the video are scattered into these zones. The seeks are then in order and the maximum search distance happens at only when crossing zones, thus the seek time can be reduced [11]. All zones have equal bandwidth and are accessed intersectantly. In this scheme, the seek time is minimized and the average bandwidth is guaranteed approximately.
To increase the throughput such as to pump numerous media streams, the placement scheme should support sequential-like and concurrent retrieval capabilities such as to further reduce the seek time and to increase pumping bandwidth.
For the disk storage, the sequential access has higher performance than the random access such that the layout of media stream should be contiguous as possible. In order to have the sequential retrieval capability, the media streams can contiguously placed onto the storage devices sequentially and disk-by-disk. However, under this scheme each disk can admit only one user to access it at one time, otherwise, the video data retrieval will become random access because of the interleaving of the video stream retrievals. In this scheme the number of users is limited. To increase the concurrent retrieval capability, the media streams should be stripped and scattered onto the disks. Nevertheless, because the spreading of the data, this scheme requires more seek operations. In order to provide sequential and concurrent retrieval capabilities simultaneously, we first divide each disk into X zones containing equal numbers of disk blocks. Each zone is a contiguous group of disk blocks. The choice of the number of X is dependent on the number of disks in the disk set.
Because the media streams are scattered onto the disks, to reduce the mapping or indexing table requirement and to let the scattered media stream layout could have the sequential retrieval capability, a special placement and scheduling scheme is designed. The placement is deal with first. From the residual number theory, we see that if two related prime numbers, named m and n, are selected as the residual bases, then the number between 0 and m*n-1 can be reconstructed from the residuals. Now consider the number of zones and the number of disks as the residual bases. Let the number of zones (ex., X) in each disk is equal to the number of disks (ex., Y) plus one, that is X=Y+1; these two numbers, X and Y, are then related prime. The position of each zone can be easily found out from the residuals without the mapping or indexing table. Media streams are then stripped (each strip block is indexed by i here) and scattered across Y disks and X zones. The ith media stream strip block is laid out in
zone = (i mod X) of (1)
disk = (i mod Y ) (2)
For example, let the disk set have four disks indexed from 0 to 3 (i.e., Y=4), and the number of zones is chosen to equal to five (i.e., X=Y+1=5) and indexed from 0 to 4, the strip blocks of the media stream are placed in the sequence as
<disk, zone> : < 0, 0>, <1, 1>, <2, 2>, <3, 3>, < 0, 4>, <1, 0>, <2, 1>, <3, 2>, <0, 3>, ...
The placement can be offset by an initial
<disk, zone> : <2, 1>, <3, 2>, <0, 3>, <1, 4>, <2, 0>, <3, 1>, <0, 2>, <1, 3>, <2, 4>, ...
This scheme alternates zones on adjacent disks and when in the transition from the last to first disk, the zone index is continued to the index of the previous cycle in each disk. This scheme organizes the disk set as a totally integrated sequence storage device. To place the media streams into the disk set, each media stream is segmented into groups of contiguous disk blocks called v_segs and the v_segs are then laid out to zones as shown.
The designed media server then utilizes a scheduling interval, a period of time (it is called the round interval in Section 2) in which data for all clients is read from the disks, for scheduling the retrieval operation. The data requested for a stream in each scheduling interval is stored in exactly one v_seg. Different bit rate media streams will have different sized v_seg, but all the v_segs will correspond to the same play time interval. To parallelize the retrieval operation, a r_scheduler scheme is used. Each disk has its independent r_scheduler in a scheduling interval. Totally, there are Y r_schedulers for the disk set with Y disks. These r_schedulers are circulated around the disks as shown in Figure 2.
![[IMG]](Image22.gif)
Figure 2. r_scheduler operation.
To retrieve a stream, it usually requires a sequence of requests where each request will ask for reading a block of data that belongs to the stream. The r_schedulers organize requests into groups that share access to the disks, and manage the disk bandwidth and disk times. The requests in each group of a r_scheduler belong to one of the streams to be retrieved. Let B represents the total bandwidth that can be accommodated by one disk in the media server, and X be the number of zones of each disk. Requests can be added to a r_scheduler only as long as all the requests in the r_scheduler use a total bandwidth less than or equal to B. The number of r_schedulers is equal to the number of disks in the disk set. Requests in one r_scheduler are arranged such that they always access the same disk in each scheduling interval. The scheduling interval is further divided into X zone periods. Within a zone period of a scheduling interval, all requests in each group which will access the same disk zone will be served. The total bandwidth used by requests in each group is kept approximately equal. When r_scheduler circulates from disk to disk as shown in Figure 2, the disk zone accessible to each request changes in accordance with the layout scheme. Assuming that all r_schedulers begin the services from the first zone, then according to our placement scheme, a r_scheduler will just serve the consecutive data blocks belonging to its requested streams in the next disk.
For example, if the v_segs of a stream file are placed in the sequence like < 0,0>, <1, 1>, <2,2>, ... Let all r_schedulers begin at disk 0. Then in the first scheduling interval, v_seg < 0, 0> will be accessed by its specific r_scheduler at disk 0. And in the next scheduling interval, v_seg <1,1> will be accessed by its specific r_scheduler at disk 1 (since all disks have moved to zone 1 at this time). This maintains the balance between zone accesses, while allowing every request to access all areas of disks and sequentially disk-by-disk. Within each r_scheduler, the read requests for a disk are ordered sequentially. At any given scheduling interval, only one r_scheduler will read data from a given disk. Each disk is assigned to one r_scheduler in every scheduling interval. For example, Y=4 disks, and X=5 zones, the operations are shown in Figure 3. The figure shows two streams and their corresponding service zone periods which are placed according the examples in Section 3.1.
When a new request arrives, the admission policy attempts to place it in the r_scheduler that will next be assigned the disk containing the first block of the stream. If that r_scheduler is full, the admission policy scans backwards for a r scheduler that will soon have access to the proper disk and zone and which has sufficient bandwidth for the new request.
![[IMG]](Image21.gif)
Figure 3. 3 r_schedulers operate over 3 disks with each disk having 4 zones, T i denotes the zone period required for retrieving a group of stream requests..
We analyze and compare our VSP RAID with a regular RAID. A regular RAID refers to a RAID system which simply strips the data into multiple parallel access disks, probably with redundant error checking, i.e., RAID 3 or RAID 5 [2]. The stripped data in each single disk is assumed to be placed in a regular manner as shown in Figure 4. There is no special retrieval scheduler over these multiple disks and stripped data. Thus the access on eachsingle disk will perform like a randomly access file system. We continue our analysis first on regular RAID in the next subsection.
![[IMG]](Image26.gif)
Figure 4. Regular placement scheme.
![[IMG]](Image23.gif)
Figure 5. A single server single queuing system.
The performance of the data retrieval scheme under multiple streams is observed in each individual stream and its is modeled by a single queuing system with a single server, as shown in Figure 5. The data in each requested stream are retrieved from the storage and enter the queue in a block-by-block basis, i.e., 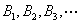 ,etc. Let
,etc. Let 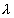 denote the mean block arrival rate and
denote the mean block arrival rate and 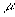 denote the mean block service rate in the system. To obtain a state of equilibrium, i.e., blocks will not be queued infinitely, it is required that
denote the mean block service rate in the system. To obtain a state of equilibrium, i.e., blocks will not be queued infinitely, it is required that 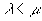 . For a stream to be played smoothly, it is also required that the queue will never be empty whenever the server has finished served the previous block.
. For a stream to be played smoothly, it is also required that the queue will never be empty whenever the server has finished served the previous block.
It has been shown that a larger block size will introduce a better disk access performance [3]. The size of a block is usually large compared with the packet size transmitted in the network. When a block is served, it will be further divided into smaller segments and sent via the network to the subscribers. The transmission rate usually depends on several dynamic parameters such as network access delay, stream consumption speed at the subscriber, and stream service quality. Therefore, without the loss of generality, we assume that the service time of each block is a random variable which is exponentially distributed. That is, the service process is a Poisson process. In this sense, we have a G/M/1 queuing model. For any type of block arrival process, we are able to obtain the probability 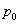 of seeing there is no queued element at any instantaneous time [12]. That is
of seeing there is no queued element at any instantaneous time [12]. That is
= 1 - 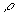 (3)
(3)
where is the utilization factor 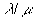 . For letting
. For letting 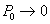 , we have a very intuitive result,
, we have a very intuitive result, 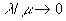 .
.
The block arrival process depends on the mixed behavior of disk access under multiple requested streams. The time period required to retrieve one block includes two major elements, namely the block transfer time and the disk head seeking time. Assume that each block has equal size and all the disks has the same data transfer speed. The disk head seeking time randomly depends on the relative position of current disk head to the reqested file location. However, there is a maximum seek time equal to the time spent in seeking from the very first sector to the last sector on the disk. Thus, the inter-arrival time between two consecutive blocks can be bounded within the total time required to retrieve one block for each stream. This implies that the system process all the requested streams in a round robin basis.
The following parameters are required in our analysis.
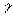 : disk data transfer rate (Bytes/sec),
: disk data transfer rate (Bytes/sec),
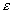 : maximum disk seeking delay (sec),
: mean block arrival rate of each stream (blocks/sec),
: mean block service rate of each stream (blocks/sec).
: maximum disk seeking delay (sec),
: mean block arrival rate of each stream (blocks/sec),
: mean block service rate of each stream (blocks/sec).
We assume that all the multimedia files in each disk will be requested with the same probability under the multi-stream environment. Thus the disk head will move randomly back and forth among the sectors and for simplicity, the seeking delay is assumed to be uniformly distributed between 0 and , where the average seeking delay would be 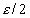 . From the above we know the time required to retrieve a block will be
. From the above we know the time required to retrieve a block will be
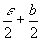 (4)
(4)
For any individual active stream, and after a block was retrieved, assume that the disk scheduler will retrieve a block for each of all other requested streams before it proceeds to retrieve the next block belonging to this stream (round robin). Then the average inter-arrival time between two consecutive blocks in any stream is
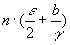 (5)
(5)
Then, we have the average block arrival rate as
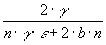 (6)
(6)
And the average block service rate is
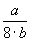 (7)
(7)
As described in the above G/M/1 queuing system, we need 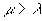 and . From Equation (3), this is
and . From Equation (3), this is 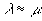 and .
and .
Given a set of above parameters, if we found . This means that the given storage system is capable enough of serving the given number of simultaneously requested streams. Thus, given a storage system with parameters b, , and , and given the required stream service rate a, we are able to find a maximal number of n such that remains very small, and denote this number as n*. And the total disk bandwidth is therefore 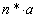 .
.
Unlike the regular RAID system, the proposed VSP RAID will not suffer from the disk seeking delay. According to the previously described queuing system, a block is said to have entered the queue only after it has been completely retrieved from the storage. This means that we assumed that the queuing system pre-loads the data into buffer by at least one block size. Given a VSP RAID with Y disks and each disk being partitioned into X zones, we note that the disk head in each disk will need the following two types of seeking delay,
However, each single stream are only affected by the above delay constantly and is independent to other streams currently in the system (this is different to the case for a regular RAID !!). Therefore, this constant seeking delay can be compensated by preloading an amount of data before playing or delivering the streams. To analyze the performance, we begin by modeling the inter-arrival time between retrieving two corsective locks for any individual streams. In Figure 6, we explain the block retrieval within the period between each disk head's rolling back. The total seeking delay within the above mentioned period is less then
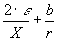 (8)
(8)
Then, we have the average block arrival rate as
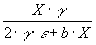 (9)
(9)
And the average block service rate remains
(10)
To have , we still need and . Thus, we need
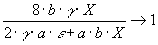 (11)
(11)
Rewrite the above expression
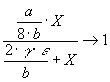 (12)
(12)
The term 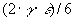 can be found to be a small number since is in the order of 10^6, is in the order of 10^-3 streams, block size, and disk seeking delay when X is sufficiently large. The results also indicates that if the disk data transfer rate is greater than the single stream service rate, then will approach zero. Therefore, the total disk bandwidth is
can be found to be a small number since is in the order of 10^6, is in the order of 10^-3 streams, block size, and disk seeking delay when X is sufficiently large. The results also indicates that if the disk data transfer rate is greater than the single stream service rate, then will approach zero. Therefore, the total disk bandwidth is 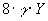 as there are Y disks all together. Under a multi-stream environment, the proposed scheme performs almost the same as a single-stream system does.
as there are Y disks all together. Under a multi-stream environment, the proposed scheme performs almost the same as a single-stream system does.
![[IMG]](Image25.gif)
Figure 7. Disk head roll-back in the proposed VSP scheme.
From Equations (6) and (7), we are able to derive the total disk bandwidthfor a regular RAID system. That is
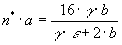 (13)
(13)
and this result shows that the total disk bandwidth of a regular RAID system depends only on the seeking delay and the disk data transfer rate . As indicated in Section 3, a typical seeking delay ranges from 8:5ms to 18ms. And from our experiment, the disk data transfer rate ranges from 4Mbytes/sec to 8Mbytes/sec. Thus, we plot the comparison in Figure 7, where is 6Mbytes/sec, 8Mbytes/sec and is 10ms, 15ms respectively. The proposed VSP scheme has a steady performance improvement over the regular RAID system. The regular RAID only performs better with large block size (i.e., 64KBytes) and small seeking delay. However, the best performance of a regular RAID is still less than the proposed VSP scheme by around 40%.
![[IMG]](Image16.gif)
Figure 7. Total disk bandwidth performance (a) g = 6MBytes, e = 10ms, (b) g = 6MBytes, e = 15ms, (c) r = 8MBytes, e = 10ms, (d) g = 8MBytes, e = 15ms.
We have implement a experimental system for both the regular RAID and the VSP scheme. The operating system is Windows NT 4.0 (TM) and the storage interface is ASPI (Adaptec SCSI Programming Interface ) (TM) Fast-and-Wide SCSI. The selected disk is a Seagate ST32550 (TM) with capacity of 2 GBytes. For regular RAID system, we place 12 large files over the disk as explained in Figure 4 and each file has identical size of 150 MBytes. We let multiple processes concurrently read data from these files under the assumption that the read process is by block and in a best effort approach. In Figure 8, we show the total disk bandwidth read by various number of concurrent process under the assumption that each process randomly selects a file from these 10 given files. When there is only one process, the system behaves like a sequential read process without seeking delay and thus a highest performance is obtained. However, when there are multiple concurrent processes, the performance will drop suddenly since there is seeking delay. In Figure 9, we show the similar result while we set that all the concurrent processes will read the same file. The performance is improved slightly since the disk seeking range is now limited in only one file.
Another experiment is the VSP scheme. We have implemented a simple prototype using our VSP scheme. We use two disks (Y=2) and let each disk is partitioned into 3 zones (X=3). We place the same 10 files into the VSP RAID and begin the retrieval experiment under multiple concurrent read processes. In Figure 10, we show the result for randomly selecting files and for reading the same file. The obtained total disk bandwidth is now up to 62Mbps for two disks. The performance reamins steady as the number of concurrent processes is increased. The performance can be improved further since we are now using Windows NT (TM) which is not a real time operating system and also the disk number can be increased.
![[IMG]](Image17.gif)
Figure 8. Total disk bandwidth performance of a regular placement method (reading different files).
![[IMG]](Image18.gif)
Figure 9. Total disk bandwidth performance of a regular placement method (reading the same file).
![[IMG]](Image19.gif)
Figure 10. Total disk bandwidth performance of the VSP placement method (Y=2, X=3).
The design of a multimedia server requires a storage which is both scalable in capacity and QoS (Quality of Services) guaranteed in retrieval. The proposed VSP scheme is now used in our video-on-demand server which is able to deliver MPEG-1 and MPEG-2 movies. Our method combines both a novel placement scheme and a well-scheduled retrieval scheduler and therefore a highly parallelized retrieval performance can be achieved. Another advantage of using our scheme is that the buffer requirement for each single stream is very small.